什么是IntelliJ IDEA

简单来说,IntelliJ Idea是目前最好的Java集成开发环境,没有之一。
为什么要迁移到Intellij IDEA
Java应该是非常依赖IDE的一门语言了,恐怕也没有几个大牛能够直接用Vim/Emacs愉快的手撸代码,Java程序员离开了IDE基本上生活不能自理,IDE的重要性不言而喻。
最近在推行、部署各种自动化工具,但个人认为,相比于各种工具,一个好的IDE更是能 极大的提升 工作效率以及编码的爽快感。
目前团队中使用的开发工具主要还是Eclipse和NetBeans,所以就想借这篇文章安利一下,希望团队中更多的人能开始尝试并喜欢上IntelliJ IDEA。
目前常用的IDE主要有3个:
- Eclipse
- NetBeans
- IntelliJ IDEA
其中,Eclipse及其衍生品是最为我们所熟知的,Eclipse开源,历史悠久,插件丰富,对一些老项目兼容性也比较好,另外有很多基于Eclipse的项目也很流行,比如STS、MyEclipse。
NetBeans使用的人稍微少一些,但它有很多比Eclipse更为优秀的地方,例如免费、Oracle自家出品,对于新标准的支持非常好、有中文语言包、界面布局更合理等。
但从目前的统计数据来看,IntelliJ Idea的市场份额已经超过了Eclipse。
IntelliJ IDEA作为一个商业化的IDE,而且是一个非常昂贵的商业化IDE(499刀/年),能够被如此多的开发人员认可,肯定有它非凡之处,简单罗列几点:
- 黑色的Darcula主题,我想应该把这个放在第一位
- 智能化的代码提示、自动补全、重复代码检查、快速修复
- 更加智能的重构工具,支持跨语言的重构
- 人性化的调试工具
- 包含大量的内建工具,开箱即用的,无须配置大量的插件
- 默认支持git/svn等多种版本控制工具
- 默认支持Maven, Gradle, Ant等多种构建工具
- 内建反编译工具,方便查看没有源码的老旧jar包
- 内建数据库管理工具,可以抛弃toad/Navicat这些东西了
- 内建REST API测试工具,可以抛弃Postman之类的测试工具了
- 支持Tomcat、JBoss、WebLogic等主流应用服务器
- Google的助攻,Android开发环境由最初基于Eclipse的ADT,迁移到了基于IDEA的Android Studio
导入一个工程
要想开始体验IntelliJ IDEA,首先要新建一个工程(Project)或导入已有的工程。这里我们选择从版本库中导入一个已有的工程。
在欢迎界面中点击最下方的 Check out from Version Control

可以看到,IntelliJ IDEA支持GitHub、CVS、Git、Svn等多种版本库。
这里我们尝试导入一个GitHub中的工程,填写自已的GitHub用户名、密码
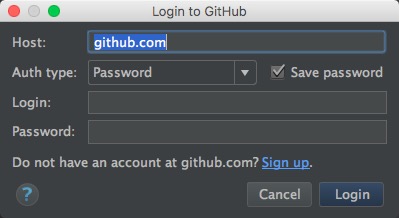
在下拉列表中选择好一个工程后,点击 Clone
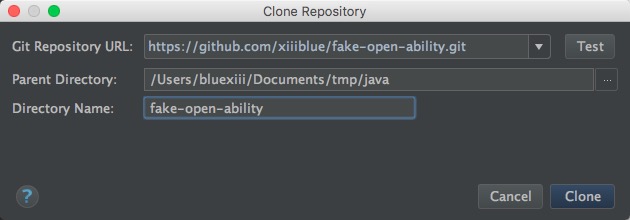
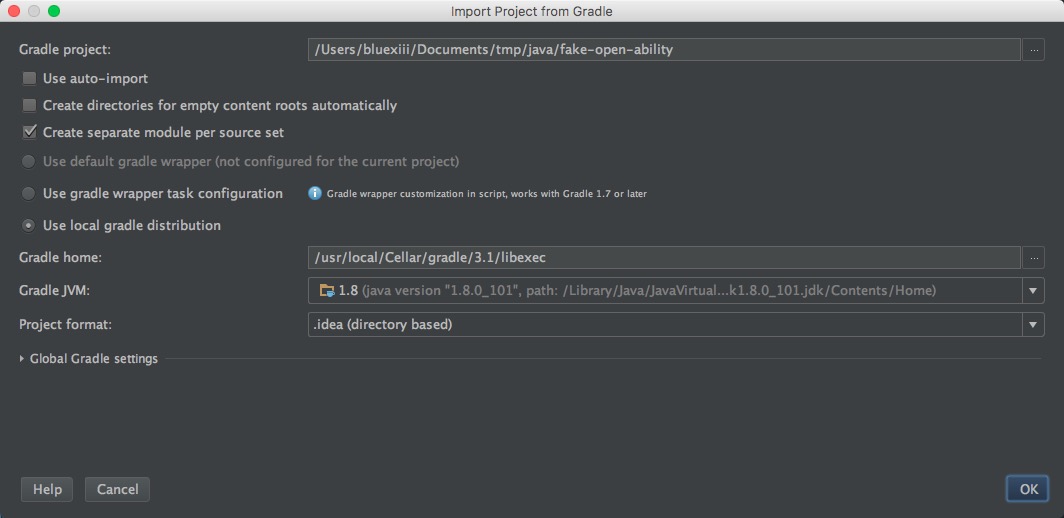
如果项目是用Gradle/Maven构建的,还会弹出一个构建工具配置界面
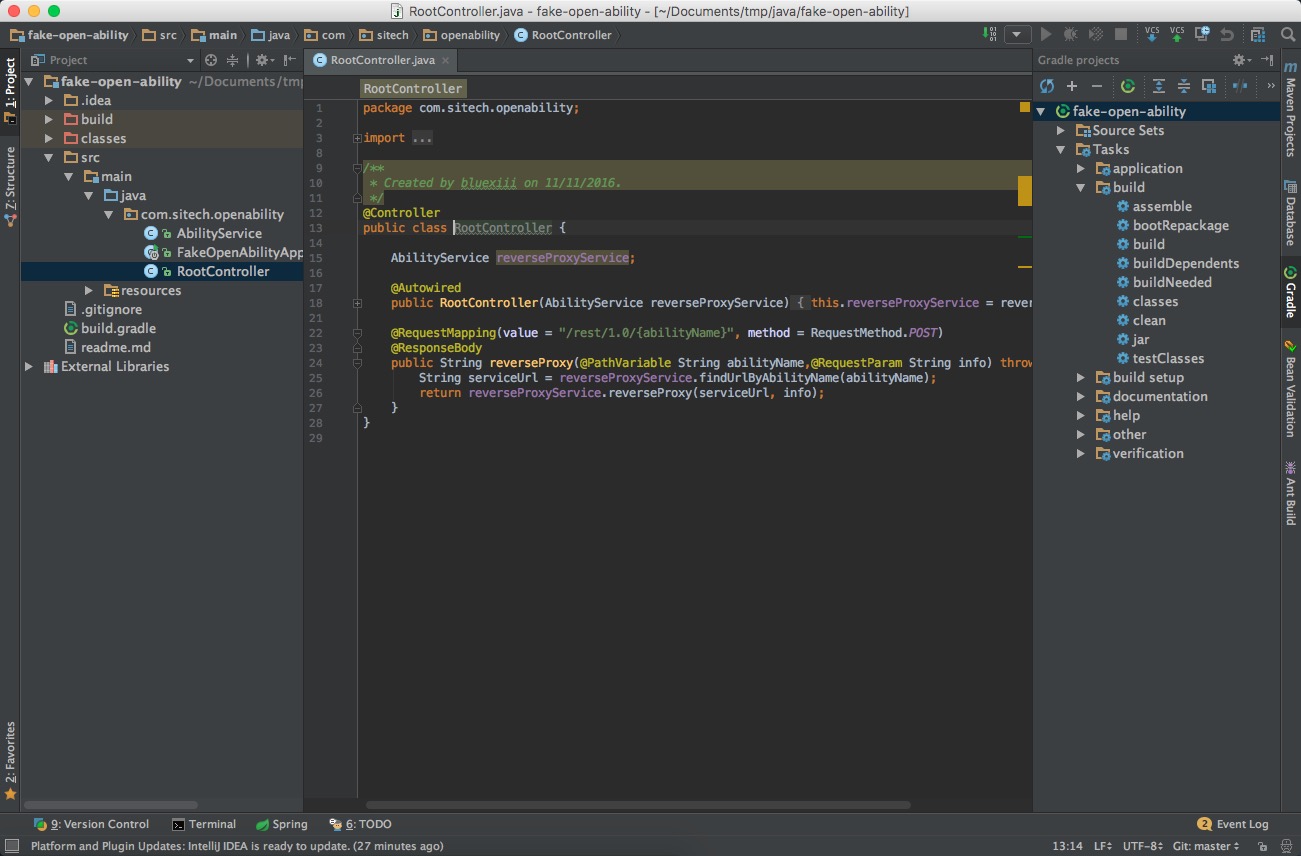
导入完成后,可以看到主界面了
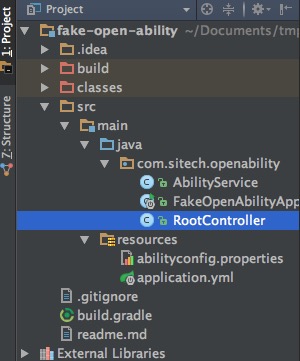
项目结构
IntelliJ IDEA中的项目结构和Eclipse有很大的不同。
- Eclipse中有workspace的概念,可以向workspace中添加多个工程。
- IDEA没有workspace,一个窗口中只能打开一个工程(Project),但一个工程中可以包含多个模块(module),这种方式更符合多模块应用开发的需求。
界面左侧的Project栏,可以查看项目中的文件结构,通过Cmd+1快捷键调出/关闭。
使用Cmd+; 快捷键,可以打开项目设置界面,在这里配置模块、库、Facets、Artifacts等。
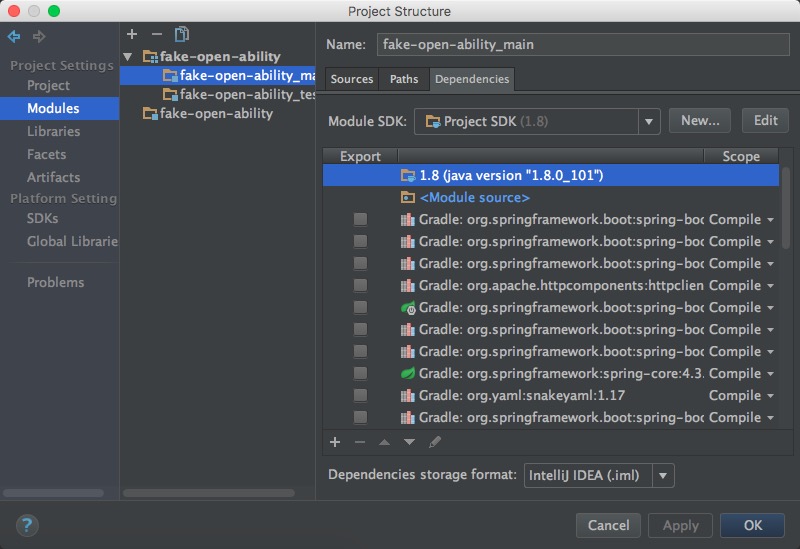
Facets
Facets可以认为是项目支持的特性,例如JPA、Spring、Hibernate等,当一个项目被IDEA扫描完毕之后,它会自动为每个模块添加相应用Facets,当然也可以手工进行添加

Artifacts
Artifacts是项目的打包部署设置。
例如,对于WEB工程而言,IDEA通过配置Artifacts,将编译输出的class文件,与jsp/html/css页面等静态文件,以特定的目录结构合并到一起。
目录图标
- 蓝色 - 源码根目录
- 绿色 - 测试代码目录
- 红色 - 需要排除的目录,例如class/build等包含二进制文件的目录
- 黄色 - 资源目录,application.yml等会放在这里面
点击Project栏中右上角齿轮图标,可以调整目录的展示方式,比如合并中间空目录等:
快捷键对比
下面是一份Eclipse与IntelliJ IDEA的快捷键比对表:
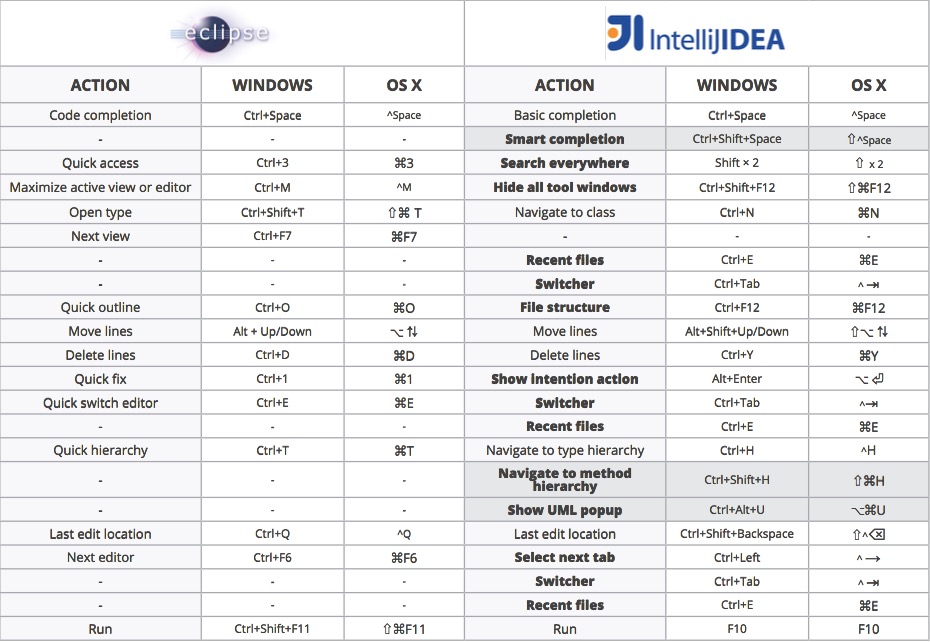
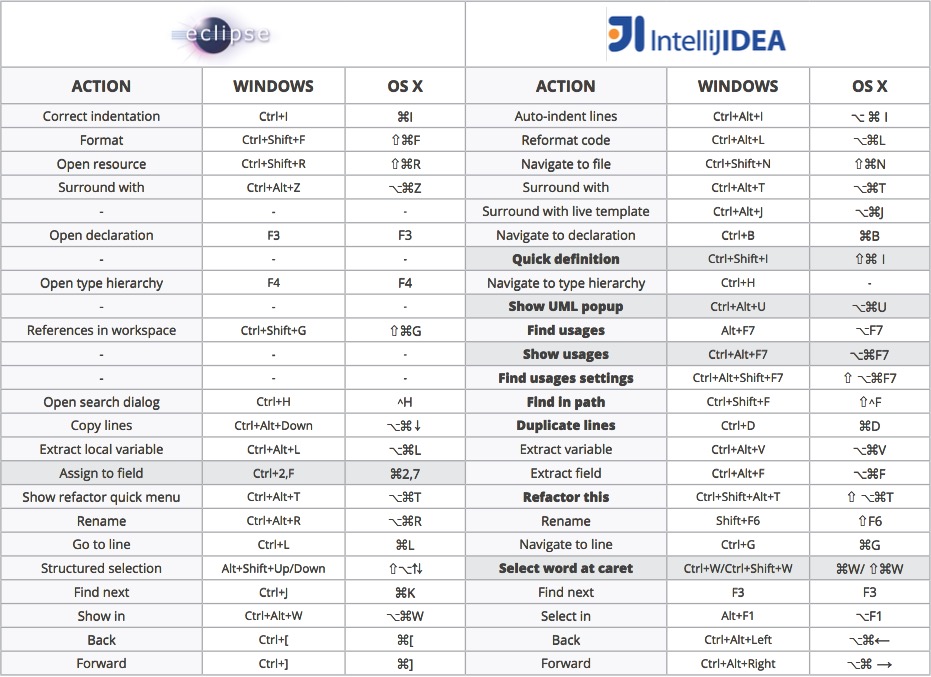
如果不想使用IDEA的默认快捷键,想沿用之前的一些习惯,IDEA也提供了几套其它的配置,使用 Ctrl+` 调出菜单
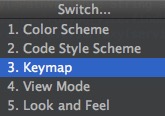
选择 3-Keymap 即可切换配置
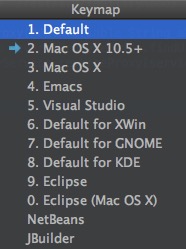
但建议还是尽量适应IntelliJ IDEA的默认快捷键配置吧。
下面有几个有趣的与其它IDE的区别:
Cmd+D
在Eclipse中,Cmd+D是删除一行,但在IntelliJ IDEA中,D是指duplicate,复制一行。 Cmd+S
在其它编辑器中,我们通常会频繁使用Cmd+S进行保存,但在IDEA中,完全不需要这么做。IntelliJ IDEA的自动保存功能做的非常好,不用担心会丢失进度,Cmd+S只能给我们带来一些心理上的”安全感”。
界面布局
IntelliJ IDEA的默认布局非常的简洁,几乎只有一个编辑器界面,甚至还可以通过Ctrl+Cmd+F全屏显示,以获得更加沉浸式的体验。
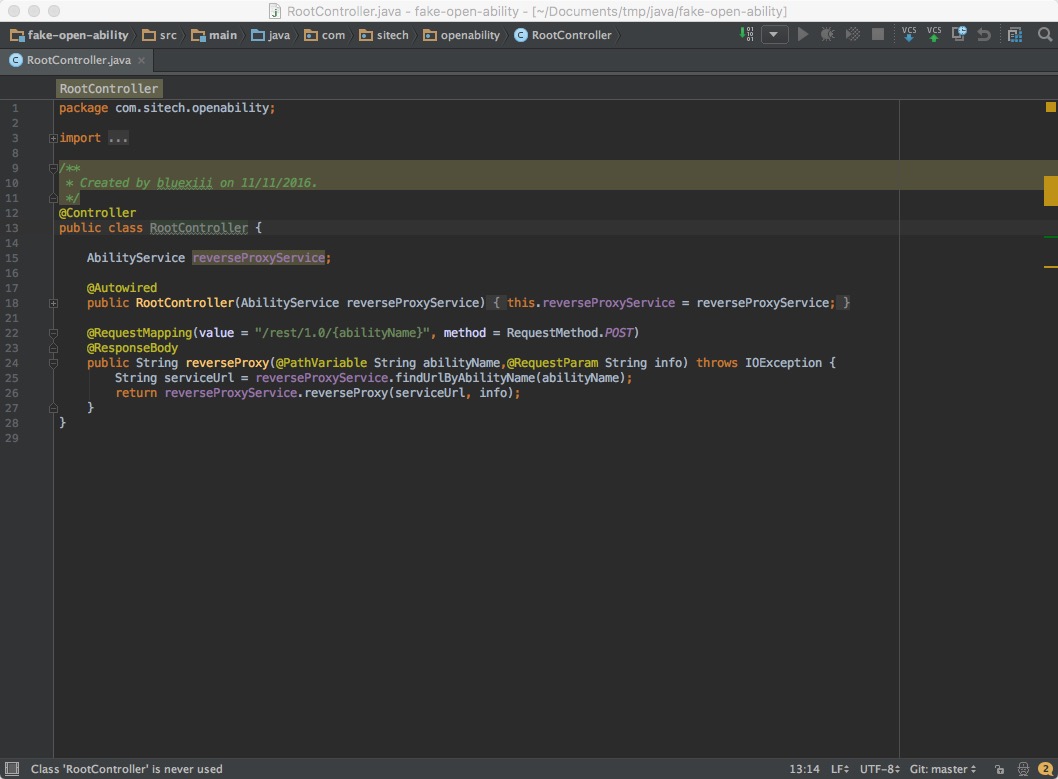
点击界面最左下角的显示器形状的图标,可以用来切换布局模式,调出或隐藏周边的工具栏
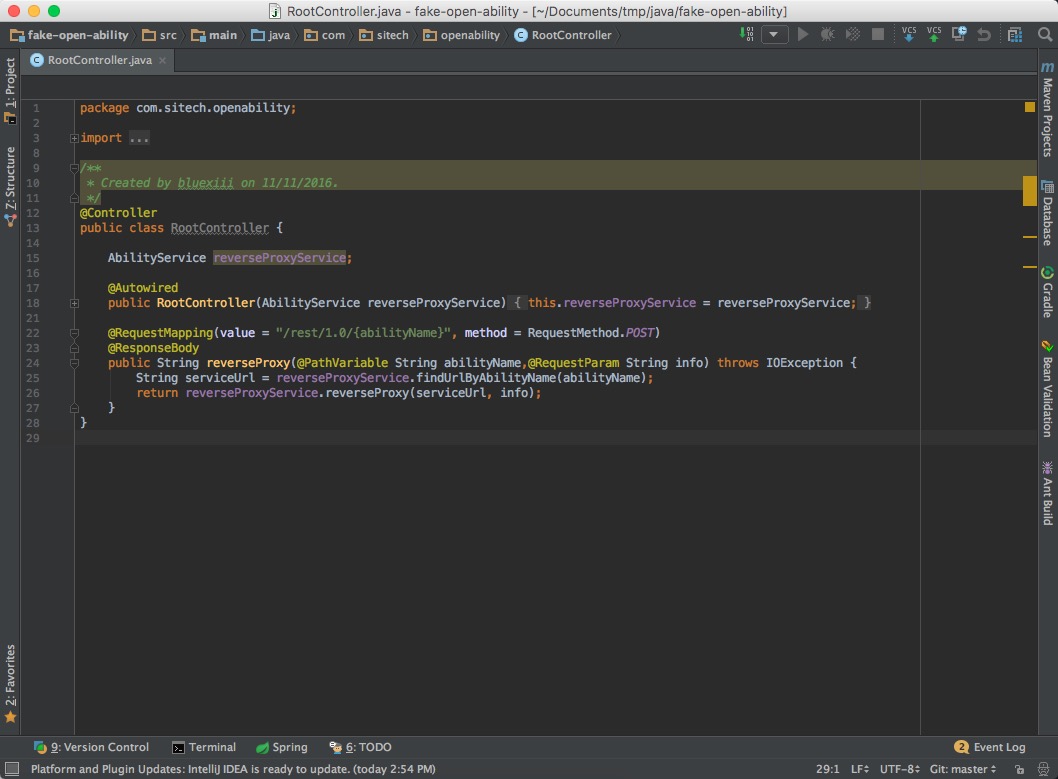
在使用精简布局时,如果要进行文件定位、打开某个侧边栏等操作,就需要使用一些快捷建进行操作了。
一般是使用Cmd+数字来显示侧边栏,例如Cmd+1显示Project栏,Cmd+9显示版本控制栏,具体数字界面上会有提示。
另外,Cmd+E不但可以显示最近使用过的文件,还可以在左侧选择打开各个侧边栏,非常好用。
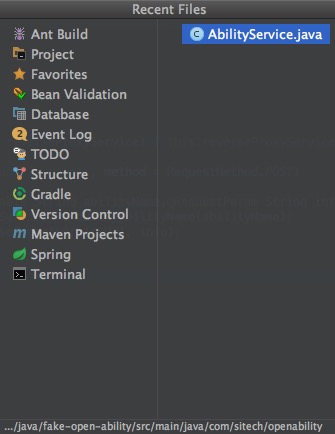
同样的,Ctrl+Tab快捷键可以实现类似的功能,并且效率更高
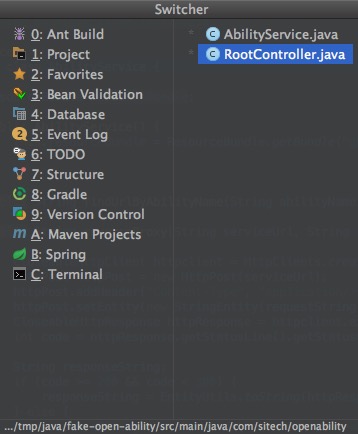
快速查找
使用Cmd+O可以弹出快速 查找类名 窗口,输入类名关键字筛选,可以快速打开类所在的源文件

使用Cmd+Shift+O可以弹出快速 查找文件名 窗口,输入文件名关键字,可以打开任意文件
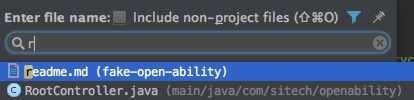
还有一个更方便的方式,如果不确定要找什么,双击shift键,可以弹出”Search Everywhere”窗口,输入关键词搜索一切吧。
当然,还可以使用之前提到过的Cmd+E,查看曾经打开过的文件。
常用设置
缩进方式配置
使用空格与TAB键缩进,在码农界争论至今还没有定论,那就不妨根据自已的喜好手工设置一下吧。
首先使用Cmd+,打开全局设置界面,在Editor → Editor Tabs中可以找到相应的选项:
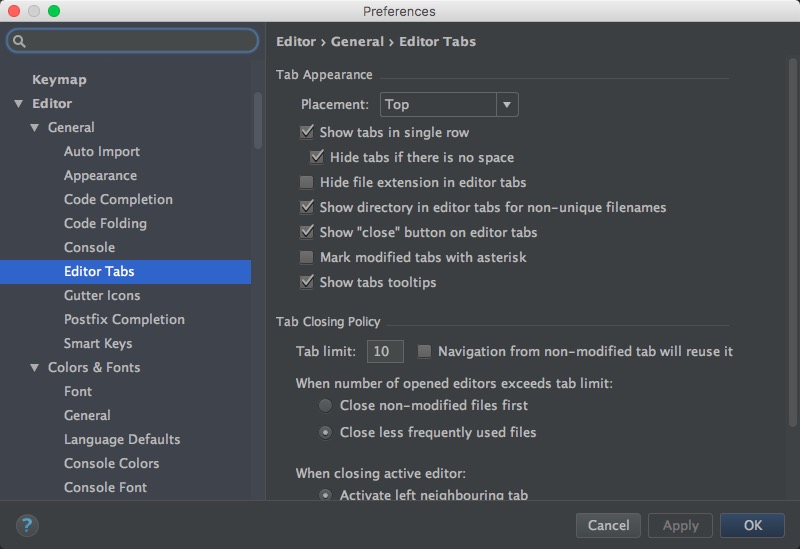
界面主题配置
在Appearance & Behavior → Appearance中,可以设置喜欢的主题,字体、字号等
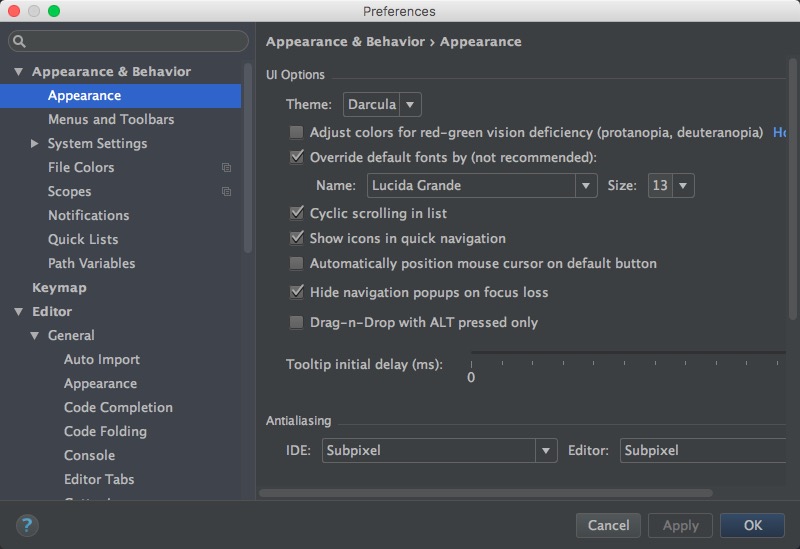
这里当然是首推Darcula主题。
代码编辑
首先要记忆的一个快捷键是Cmd+F12,可以打开 class outline 窗口,查看文件中的各个方法。
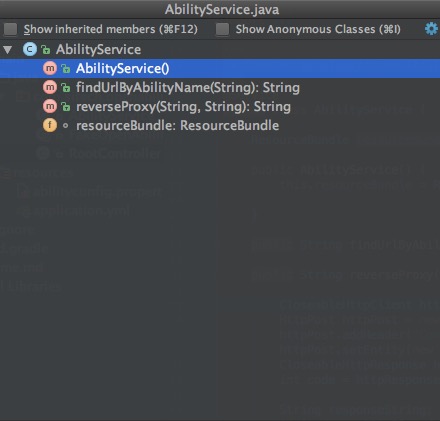
类似的也可以通过Ctrl+H打开 type hierarchy 侧边栏
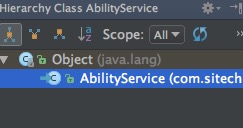
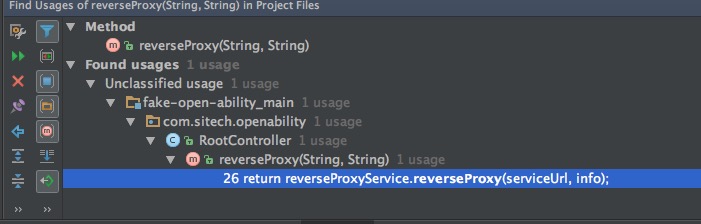
另外,还可以使用Alt+F7,打开 Find Usages 底边栏,显示方法的使用者。
自动补全
使用Ctrl+Space,可以进行代码自动补全。
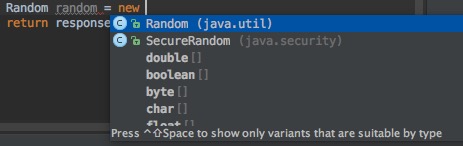
Ctrl+Shift+Space,是更加智能的代码补全,它会猜测你的意图,只展示最有用的结果
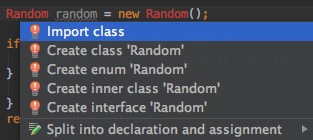
另外Alt+Enter也十分有用,当使用了一个类,但它还没有被导入时,可以用它来快速导入
代码生成
使用Cmd+N可以自动生成代码,比如Getter/Setter/toString()等等

代码重构
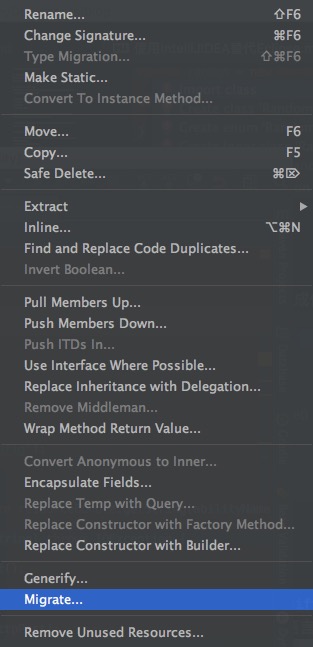
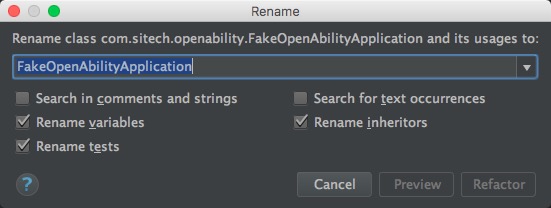
最简单的,可以通过右键菜单或Shift+F6进行重命名,可以是文件,也可以是类名、方法名、变量名等,点击确认后IntelliJ IDEA会跨语言检索全部代码(包括.html/.js),找到所有相关的地方一起修改。
插入模版
输入特定的关键字,按TAB后,可以直接在光标处插入模板代码。
例如,首先输入psvm

然后按下TAB键,就会自动插入一个main方法的模版,相当快捷

其它重要的快捷键
- 格式化代码 -
Cmd+Alt+L
- 编译 -
Cmd+F9
- 关闭某个侧边栏 -
Shift+ESC
查找快捷键的快捷键
到现在为止,已经接触了IntelliJ IDEA的不少快捷键了。
其实对于学习一个文本编辑器也好、IDE也好,要想用的得心应手,记忆大量的快捷键都是少不了的步骤。
但如果记不清快捷键怎么办,去哪里查呢?幸好IntelliJ IDEA为我们提供了一个终级快捷键 Cmd+Shift+A,这是一个用来 查找快捷键的快捷键 !其它所有的快捷键都忘了也没有关系,只要记得这一个。。。

配置Tomcat
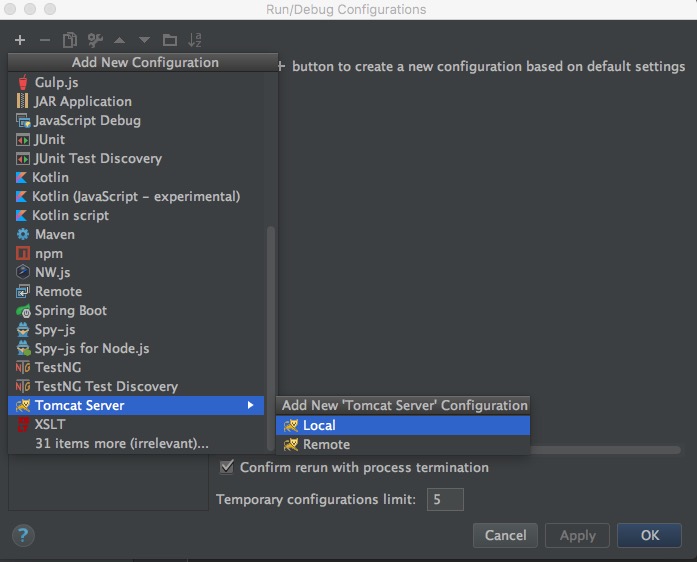
对于Web应用,如果想在本机直接运行测试,除了使用Maven等构建工具内嵌的Application Server之外,还可以选择直接在IntelliJ中配置一个。
注意请提前配置好Artifacts,然后点击顶部右侧的 Run Configuration 按钮,在新窗口中点击左上角加号,选择Tomcat即可:
代码检查
在向版本库中提交时,可以在右侧选择进行一些提交前的处理,如代码检查、格式化等:

收藏夹
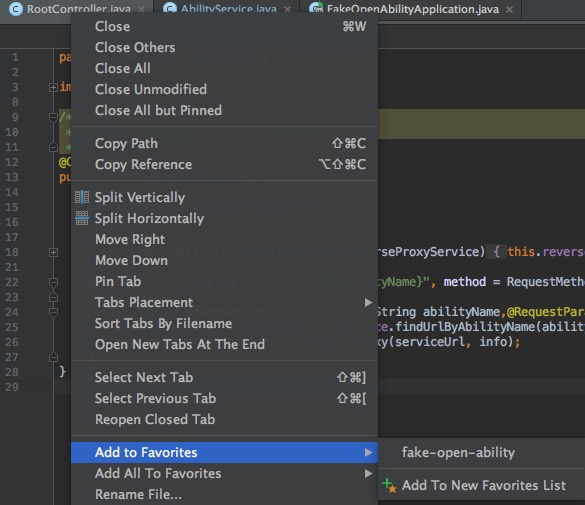
在Tab页上点击右键,可以选择Add to Favorites
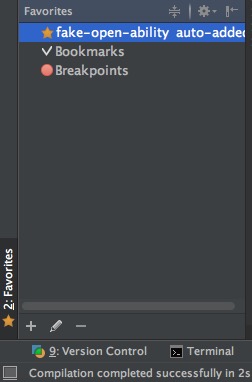
然后在左下方的Favorites栏中就可以看到了
版本控制
在窗口左下方的 Version Control 栏中,可以查看到做过变更的文件
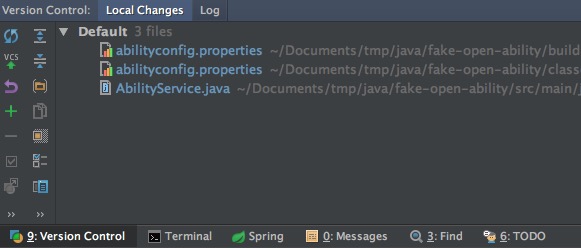
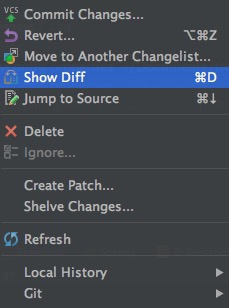
在文件上右键,可以进行代码差异比对,回滚等操作
在窗口右上方的工具栏中,可以快速Update/Commit

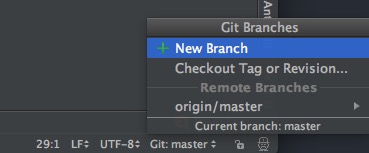
在窗口右下方的工具栏中,可以查看/新建/切换Git分支
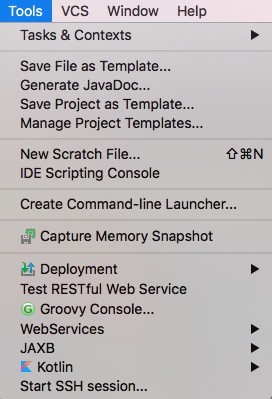
内嵌工具
菜单栏中,Tools一项中,可以找到很多内嵌的工具,比如很常用的Rest测试工具
数据源配置
在右侧的Database工具栏中,可以配置常用的数据源
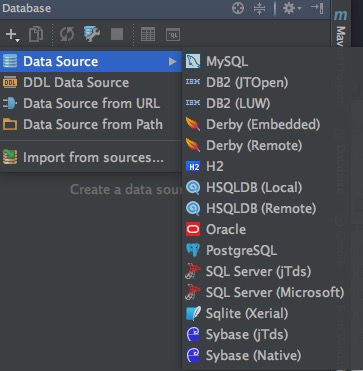
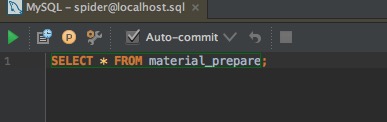
配置好之后,就可以使用内嵌的数据库查询管理工具了,另外在编写配置文件或SQL/JPQL时,也会有对应用智能提示
官方文档
以上介绍的,只是IntelliJ IDEA众多功能中的冰山一角,想要了解更多,请进一步参考官方文档:
另外官网上也提供了很多的视频教程,其中有不少小技巧。