参考文档
常用查询
1 | db.getCollection('policy_content').find({}) |
1 | db.getCollection('policy_content').find({}) |
八爪鱼
后羿
https://github.com/kingname/GeneralNewsExtractor
Python3 网络爬虫宝典
https://juejin.cn/post/6844903912349122573
https://github.com/mobz/elasticsearch-head
https://www.elastic-kaizen.com/
https://github.com/ElasticHQ/elasticsearch-HQ
docker run -p 5000:5000 elastichq/elasticsearch-hq
open http://localhost:5000/
https://github.com/appbaseio/dejavu/
1 | docker run -p 1358:1358 -d appbaseio/dejavu |
https://www.ruanyifeng.com/blog/2017/08/elasticsearch.html
https://cloud.tencent.com/developer/article/1547867
https://juejin.cn/post/6844903919013855240
https://www.elastic.co/guide/cn/elasticsearch/guide/current/query-dsl-intro.html
https://n3xtchen.github.io/n3xtchen/elasticsearch/2017/07/05/elasticsearch-23-useful-query-example
https://www.jianshu.com/p/eb30eee13923
https://zhuanlan.zhihu.com/p/34240906
https://feifeiyum.github.io/2020/02/27/es-mapping/
https://cloud.tencent.com/developer/article/1189279
https://www.ruanyifeng.com/blog/2017/08/elasticsearch.html
https://www.jianshu.com/p/7ca9e5b02ef6
https://www.elastic.co/guide/cn/kibana/current/setup.html
1 | # 查看 |
1 | # 查询 |
1 | # match_all |
1 | GET /crawl_log |
1 | # 创建一个索引 |
1 | # 查看别名 |
1 | POST /_reindex?slices=9&refresh&wait_for_completion=false |
1 | # 创建索引 |
1 | # 清空索引 |
1 | curl -X GET 'http://localhost:9200/_cat/indices?v' |
1 |
|
1 | SELECT offer_id |
同事的一个新需求,需要在AIX上以shell脚本的方式,调用sqlplus客户端连接Oracle数据库,调用mysql客户端连接MySQL数据库。
想尽量简化开发,只用纯脚本方式实现,不想替换为Java或其它方案,且不想远程调用其它Linux主机上的客户端。
故需要在AIX上安装两个客户端(只有普通用户权限,没有root权限)。没什么太特别的地方,简单记录一下过程。
Oracle接供了AIX下的InstantClient二进制zip包,其中包含了sqlplus,安装起来比较简单,主要注意一下环境变量的设置。
这里是Oracle Instant Client的下载地址 ,目前最新版本是11.2.0.1.0

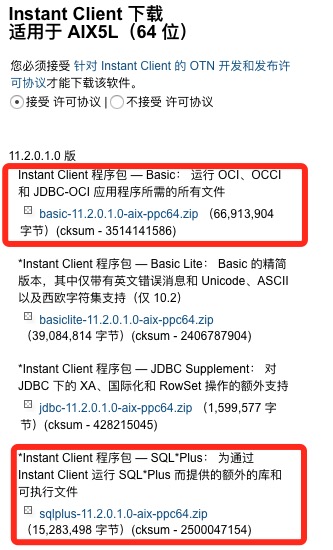
将下载好的两个包 basic-11.2.0.1.0-aix-ppc64.zip 和 sqlplus-11.2.0.1.0-aix-ppc64.zip上传至服务器,使用unzip解压至同一目录,例如: /path/to/instantclient。
编辑.profile文件,加入以下两行:
1 | export PATH=$PATH:/path/to/instantclient |
注意AIX下要设置LIBPATH环境变量,且只能填写InstantClient一个目录,不能用冒号分割加入其它目录。
MySQL官网 目前只提供5.5~5.7的下载,且二进制ZIP包和RPM/DEB包主要针对Linux的各个发行版,没有对应的AIX版本。
连源码包也是”Generic Linux”的,在AIX下编译的话编译器和依赖都会有问题。Google上可以搜索到MySQL 5.1版本在AIX下成功编译的案例(需要一些trick),不过老源码目前在官网已经下载不到了。
第三方网站bullfreeware提供了5.5版本的RPM包。此种方式有安全风险,不过已经是唯一的方案了。
MySQL-client-5.5.10-1.aix5.3.ppc.rpm
编辑.profile文件,加入PATH:
1 | export PATH=$PATH:/path/to/mysqlclient |
至此安装完毕
个人知识管理,又名PKM(Personal Knowledge Management), 是一种个人收集,验证,存储,搜索,提取,分享知识的过程。 –WIKI
PKM其实是一个很大的命题,包含了很多方面的内容。但我们每个人都在或多或少的使用它,都有自已的一些工具、心得。
以下仅讨论一下具体的笔记、摘录等文档的 编写 与 保存。
Markdown是一种轻量级标记语言,它允许人们“使用易读易写的纯文本格式编写文档,然后转换成有效的XHTML(或者HTML)文档”。这种语言吸收了很多在电子邮件中已有的纯文本标记的特性。
MarkDown第一眼看上去这个样子的:
左侧是”源码”,右侧是渲染好的”结果”
MarkDown有很多先天的优势,决定了它非常适合用来编写文档、记录笔记、撰写文章:
MarkDown语法非常简单,下面列出一些基本的标记:
1 | 标题: |
MarkDown不需要专门工具就可以编写,任何纯文本编辑器都可以胜任。但选择一款适合自已的工具可以提供代码高亮,实时预览,自定义主题,PDF导出等高级功能,极大的提升我们的写作体验。
以下列出一些比较热门的工具:
全平台:
Atom 不用过多介绍了,GitHub出品,被称为是新时代的文本编辑器,Emacs的精神继承者。通过非富的插件,很好的支持MarkDown,并提供了无限的可能性。
Sublime Text 3 更不用介绍了,同样是利用插件支持。
MarkEditor 商业软件,使用Electron写的跨平台应用。功能强大,缺点是启动速度较慢。
Mac平台:
Mweb 商业软件,作者是国人。
Mou 商业软件,Mac下老牌的编辑器了。
MacDown 功能与Mou基本相同,免费使用。
Typora 所见即所得的编辑器,输入MarkDown标记后会立刻渲染出结果。
Win平台:
MarkdownPad Win下的工具比较少,这是个不错的。
目前笔者常用的是Atom,跨平台,可以很好在工作在macOS和Ubuntu上。另外因为是通用型的编辑器,且插件非富,不仅限于写MarkDown,其它工作也可以胜任。
上面提到的工具各有特色,可以都试用一下再选一款适合自已的。
因为MarkDown是纯文本格式,所以决定了它不可能像Microsoft Word那样内嵌图片。
虽然在平时使用MarkDown做个人知识记录的过程中,是极少使用图片的。但如果要撰写给别人看的博客、教程一类的文档,有一些图片总是好的。
MarkDown可以使用本地图片,也可以使用URL远程图片。
不推荐使用本地图片,虽然图片保存在本地比扔在图床上更”安全”,丢失的风险更小,但本地散乱图片会增加我们文件夹的容量,增加文档管理的难度。而且包含本地图片的文章要发布到博客上时,通常需要一张张手工上传图片,费时费力。
所以选择一个靠谱的图床,将图片上传后,以URL的方式嵌入MarkDown是最佳选择。鉴于国内的网络环境,以及前一段时间各大云存储厂商的所做所为,国内靠谱的图床确实不多,这里只推荐 七牛云。
七牛云的CEO是许式伟,曾是金山WPS2005的首席架构师,大神级的人物,所以七牛云的技术方面我们不用过多担心。重度用户可以适当付费支持一下,让七牛云良性的发展下去。
七牛云不仅仅是图片存储这么简单,具体的特性不一一介绍了,注册后可以慢慢在官网上看文档。
解决了图床的问题,再来看一下如何使用工具快速将图片上传,并获取生成的URL。
因为每插入一张图片,都要找开网站,点击上传按钮,找到存在本地磁盘上的图片,点击确定,成功后然后再把URL复制下来,实在是很繁琐。
这里推荐一个Mac下的小工具 iPic ,下面是一个演示动画:
https://ww2.sinaimg.cn/large/006tNc79gw1fah02zweq2g30j60as7wh.gif
除了拖拽,还有更快捷的操作方式,只要选中本地图片或者复制网页中的图片,然后按下Command+U快捷键就可自动上传并获取URL。
MarkDown文档写好了,保存在本地。一切看上去都很美好,但接下来,我们又有了更多的需求:
坚果云 是国内一款非常类似于DropBox的云存储应用,它提供了 全平台 的非常 快速 且 稳定 的 增量同步 功能。
坚果云可以说是国内硕果仅存的一家了,它的增量同步在国内做的是最好的,与百度云等不同,它专注于”同步”,而不是电影等大文件的存储。
坚果云的客户端做的也是非常用心,Linux下可以全功能完美使用。手机和iPad上的APP做的也不错。希望坚果云好好存活下去。
坚果云的使用非常简单,这里有一个视频教程:
视频教程链接
目前市面上有非常多的跨平台的云笔记工具可以做到上面的事情,而且可能做的更好。 例如为知笔记、有道云笔记、EverNote、EssentialPIM等,另外还有一些后起之秀。
为什么还要使用 MarkDown + 坚果云 这样看上去略显繁琐的组合?
基于以上几点,我最终选择了使用 MarkDown + 坚果云 这样的组合进行个人知识管理,并准备长期使用下去。
版本控制系统(Version Control System,简称VCS)是一种记录一个或若干文件内容变化,以便将来查阅特定版本修订情况的系统。
按类型可以分为:
本地版本控制系统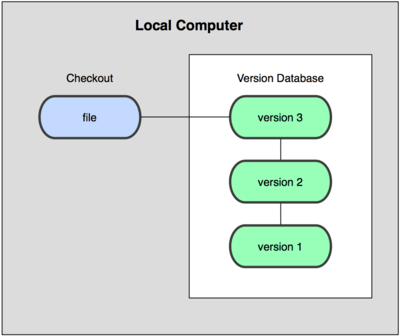
例如RCS(至少我是从来没有用过)
本地版本控制系统解决了版本的管理问题,再也不用时不时的把工程目录,通过手工拷贝的方式来存档了。但本地版本控制系统的缺点是,无法解决多人协作的问题。
集中化的版本控制系统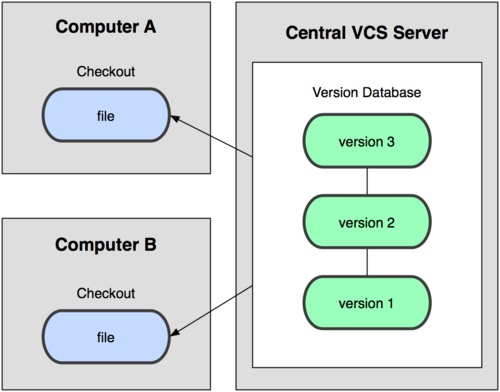
例如CVS,SVN等(公司中SVN应该用的比较多)
有一个集中管理的服务器,所有开发人员通过客户端连到这台服务器,取出最新的 文件 或者提交更新。管理员可以掌控每个开发者的权限。
集中化的VCS不但解决了版本控制问题,还可以多人协作。但缺点也是有的,就是太依赖于远程服务器,CVS服务器宕机后,会影响所有人的工作。版本记录只保存在一台服务器上,会有数据丢失风险。
分布式版本控制系统
例如Git
客户端并不只提取最新版本的文件,而是把 代码仓库 完整地镜像下来。每一次的提取操作,实际上都是一次对 代码仓库 的完整备份。
所以并没有”中心服务器”的概念,所谓的”Git服务器”,也同每个人的电脑一样,只是为了多人协作时,方便大家交换数据而已。
Git是目前世界上最先进的分布式版本控制系统(没有之一)
好不好用,看看它的开发者是谁就知道了:Linux之父 Linus Torvalds
小历史: Linux内核社区原本使用的是名为BitKeeper的商业化版本控制工具,2005年,因为社区内有人试图破解BitKeeper的协议,BitMover公司收回了免费使用BitKeeper的权力。
Linus原本可以出面道个歉,继续使用BitKeeper,然而并没有。。。Linus大神仅用了两周时间,自已用C写了一个分布式版本控制系统,于是Git诞生了!
为什么要使用Git,或者说Git相比SVN有什么优势呢?
分布式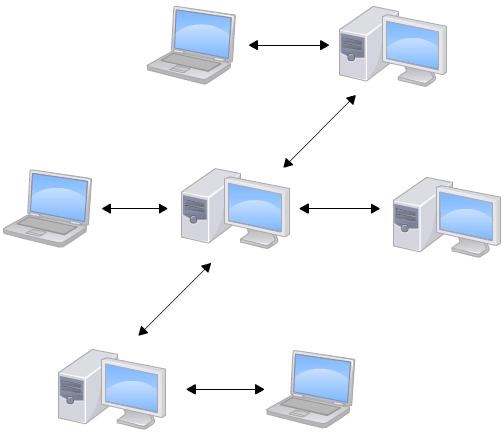
分支管理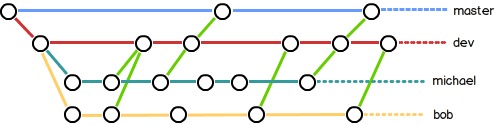
GitHub

Git和其他版本控制系统的主要差别在于,Git只关心文件数据的 整体 是否发生变化,而大多数其他系统则只关心 文件内容 的具体差异。
SVN在每个版本中,以单一文件为单位,记录各个文件的差异: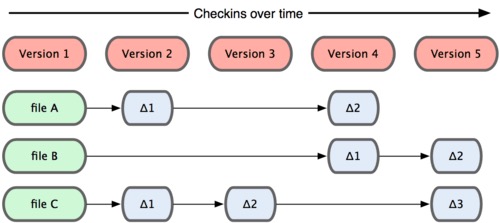
Git在每个版本中,以当时的全部文件为单位,记录一个快照:
Git的绝大多数操作都只需要访问本地文件和资源,不用连网。因为你的本机上,就已经是完整的代码库了。这样一来,在无法连接公司内网的环境中,也可以愉快的写代码了。
例如,如果想看当前版本的文件和一个月前的版本之间有何差异,Git会取出一个月前的快照和当前文件作一次差异运算,而不用每次都请求远程服务器。
在保存到Git之前,所有数据都要进行内容的校验和(checksum)计算,并将此结果作为数据的唯一标识和索引。
这项特性作为Git的设计哲学,建在整体架构的最底层。所以如果文件在传输时变得不完整,或者磁盘损坏导致文件数据缺失,Git都能立即察觉。
Git使用SHA-1算法计算数据的校验和,通过对文件的内容或目录的结构计算出一个SHA-1哈希值,作为指纹字符串。该字串由40个十六进制字符组成,看起来就像是:24b9da6552252987aa493b52f8696cd6d3b00373
Git的工作完全依赖于这类指纹字串,所以你会经常看到这样的哈希值。实际上,所有保存在 Git数据库中的东西都是用此哈希值来作索引的,而不是靠文件名。
常用的Git操作大多仅仅是把数据添加到数据库,很难让Git执行任何不可逆操作。在Git中一旦提交快照之后就完全不用担心丢失数据,特别是养成定期推送到其他仓库的习惯的话。
对于任何一个文件,在 Git 内都只有三种状态:已提交(committed) 已修改(modified) 已暂存(staged)
已提交表示该文件已经被安全地保存在本地数据库中了;
已修改表示修改了某个文件,但还没有提交保存;
已暂存表示把已修改的文件放在下次提交时要保存的清单中。
由此我们看到 Git 管理项目时,文件流转的三个工作区域:Git 的工作目录,暂存区域,以及本地仓库。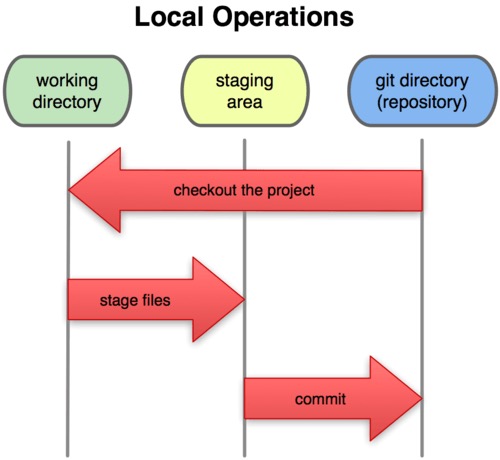
每个项目都有一个名为.git的目录,它是 Git用来保存元数据和对象数据库的地方。该目录非常重要,每次克隆镜像仓库的时候,实际拷贝的就是这个目录里面的数据。
从项目中取出某个版本的所有文件和目录,用以开始后续工作的叫做工作目录。这些文件实际上都是从Git目录中的压缩对象数据库中提取出来的,接下来就可以在工作目录中对这些文件进行编辑。
所谓的暂存区域只不过是个简单的文件,一般都放在 Git 目录中。有时候人们会把这个文件叫做索引文件,不过标准说法还是叫暂存区域。
基本的 Git 工作流程如下:
所以,我们可以从文件所处的位置来判断状态:如果是Git目录中保存着的特定版本文件,就属于已提交状态;如果作了修改并已放入暂存区域,就属于已暂存状态;如果自上次取出后,作了修改但还没有放到暂存区域,就是已修改状态。
有两种取得Git项目仓库的方法。第一种是在现存的目录下,通过导入所有文件来创建新的Git仓库。 第二种是从已有的Git仓库克隆出一个新的镜像仓库来。
如果一个目录还没有使用Git进行管理,只需到此项目所在的目录,执行git init,初始化后,在当前目录下会出现一个名为.git的目录
1 | $ mkdir learngit |
如果Git项目已经存在,可以使用git clone从远程服务器上复制一份出来,Git支持多种协议:
1 | $ git clone mobgit@134.32.51.60:learngit.git #使用SSH传输协议 |
使用git status命令可以查看文件的状态
1 | $ git status |
出现如上的提示,说明现在的工作目录相当干净,所有已跟踪文件在上次提交后都未被更改过。
现在我们做一些改动,添加一个readme.txt进去,然后再看一下状态
1 | $ cat>readme.txt |
Untracked files显示了这个新创建的readme.txt处于未跟跟踪状态
使用git add命令开始跟踪一个新文件
1 | $ git status |

readme.txt已 被跟踪 ,并处于 暂存状态
现在我们再对readme.txt进行修改,添加一行,再执行git status查看状态
1 | $ git status |
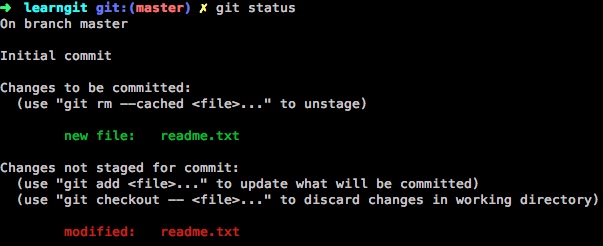
可以看到readme.txt 不仅出现在了Changes to be committed,还出现在了Changes not staged for commit
由此可见,Git关心的是 Changes ,而不是文件本身。
再次执行git add,可以将 本次修改 提交到暂存区,Changes not staged for commit提示消失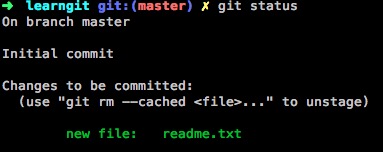
使用git commit命令将暂存区中的内容提交至版本库,工作区又是干净的了
1 | $ git commit -m "my first commit" |
注意:一定要使用-m参数加入注释,认真描述本次的提交具体做了些什么,这对于以后我们查询历史记录非常重要。
如果觉得使用暂存区过于繁琐,可以在commit时直接使用-a参数,Git就会自动把所有已经跟踪过的文件暂存起来一并提交,从而跳过git add步骤。
1 | $ git commit -a -m "my first commit" |
使用git log命令可以查看历史记录
1 | $ git log |
可以看到,每次更新都有一个SHA-1校验和、作者的名字和电子邮件地址、提交时间、提交说明。
撤消操作在这里这里不做重点描述了,只列出几个常用命令。
修改最后一次提交:
git commit –amend
取消已经暂存的文件:
git reset HEAD readme.txt
取消对文件的修改:
git checkout – readme.txt
之前介绍了在本地仓库的一些操作。但当与他人协作开发某个项目时,需要至少使用一个远程仓库,以便推送或拉取数据,分享各自的工作进展。
之前已经在讲新建仓库时已经提到,如何克隆远程库,这里再重复列一遍:
1 | $ git clone mobgit@134.32.51.60:learngit.git #使用SSH传输协议 |
如果之前我们使用的git clone命令直接克隆了一个远程仓库到本机,Git就已经默认绑定了一个名为origin的远程库。当然我们还可以手工绑定其它远程库,远程仓库可以有多个。
使用git remote -v命令列出我们绑定了哪些远程库:
1 | $ git remote -v |
接下来还可以使用git remote show origin来查看这个名为origin的远程库的更详细的信息,这里先不细讲
1 | $ git remote show origin |
我们先让管理员新建一个名为learngit2的远程仓库,再使用remote add命令将它添加进来,取名为repo2
1 | $ git remote add repo2 mobgit@134.32.51.60:learngit2.git |
现在我们有origin和repo2两个远程仓库了
使用git fetch [remote-name]从远程仓库抓取数据,注意fetch命令只是将远端的数据拉到本地仓库,并不自动合并到当前工作分支(关于分支稍后讲解)
例如要抓取名为origin远程仓库:
1 | $ git fetch origin |
使用git push [remote-name] [branch-name]将本机的工作成果推送到远程仓库
例如要将本地的master分支推送到origin远程仓库上:
1 | $ git push origin master |
也许到之前为止,大家会觉得Git和Svn除了实现原理不同以及实现了分布式之外,在日常使用上并没有什么太大的区别(甚至更繁琐)。但接下来的分支,才是Git的精髓部分。
举个简单的例子:假设你准备开发一个新功能,但是需要两周才能完成,第一周你写了50%的代码,如果立刻提交,由于代码还没写完,不完整的代码库会导致别人不能干活了。如果等代码全部写完再一次提交,又存在丢失每天进度的巨大风险。
于是你创建了一个属于你自己的分支,别人看不到,还继续在原来的分支上正常工作,而你在自己的分支上干活,想提交就提交,直到开发完毕后,再一次性合并到原来的分支上,这样,既安全,又不影响别人工作。
相比于Svn等工具,Git创建、切换分支的开销是非常小的,Git鼓励 频繁使用分支
要理解分支,需要继续深入一下Git的工作原理
在Git中提交时,会保存一个提交对象(commit object),该对象包含一个指向暂存内容快照的指针,并同时包含本次提交的作者等相关附属信息,包含零个或多个指向该提交对象的父对象指针(首次提交是没有直接祖先的,普通提交有一个祖先,由两个或多个分支合并产生的提交则有多个祖先)。
假设在工作目录中有三个文件已经 修改 过,准备将它们暂存后提交。git add暂存操作时,会对 每一个文件 计算校验和,然后把当前版本的文件快照使用 blog对象 保存到Git仓库中(为提高性能,若文件没有变化,Git不会再次保存)。将它们的SHA-1校验和加入到暂存区域等待提交。git commit提交操作,时,Git首先会计算 每一个子目录 的校验和,然后将这些校验和保存为 tree对象 。 然后Git会创建一个 commit对象 ,它包含指向这个树对象的指针及注释、提交人、邮箱等信息。
现在,Git仓库中有五个对象:三个blob 对象(保存着文件快照);一个树对象(记录着目录结构和blob对象索引)以及一个提交对象(包含着指向前述树对象的指针和所有提交信息)。
单个提交对象在仓库中的数据结构: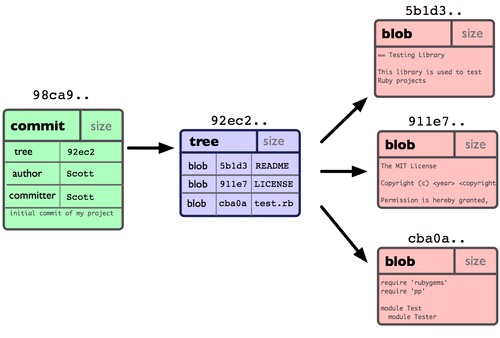
多个提交对象之间的链接关系: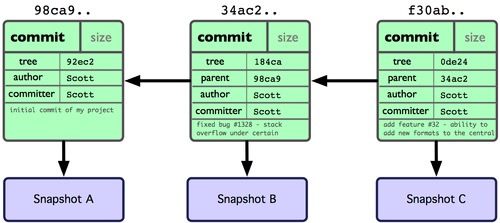
Git 中的分支,其实本质上仅仅是个指向commit对象的可变指针。Git会使用master作为分支的默认名字。在若干次提交后,你其实已经有了一个指向最后一次commit对象的master分支。它在每次提交的时候都会自动向前移动。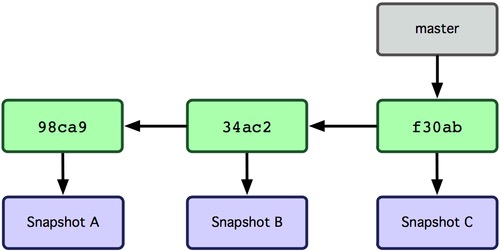
创建名为testing的新的分支,本质上就是创建一个指针,可以使用git branch命令:
1 | $ git branch testing |

Git 是如何知道你当前在哪个分支上工作的呢?其实答案也很简单,它还保存着一个名为HEAD的特别指针。它是一个指向你正在工作中的本地分支的指针。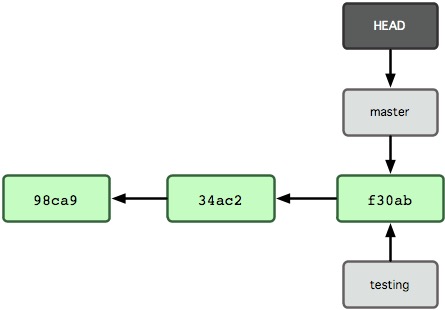
切换分支,本质上就是移动HEAD指针。
要切换到其他分支,可以执行git checkout命令。我们现在转换到刚才新建的testing分支:
1 | $ git checkout testing |
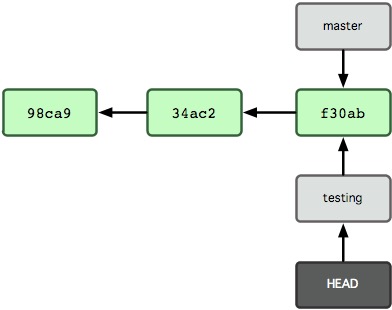
为了更好的理解分支,我们接下来模拟实际工作中的场景,进行一系列的切换操作。
现在我们已经处于testing分支了,目前testing分支和master分支都是指向同一个commit,所以我们的工作区的内容现在还没有什么变化。
现在,我们要在testing分支上做一些文件修改,然后commit:
1 | echo "testing branch">>readme.txt |
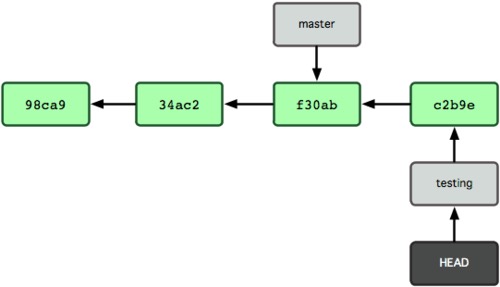
提交后,产生了一个新的commit对象,并且HEAD随着当前testing分支一起向前移动。而master分支则是停在原地不动。
我们可以试着使用git checkout命令切回master分支,看看发生了什么:
1 | $ git checkout master |
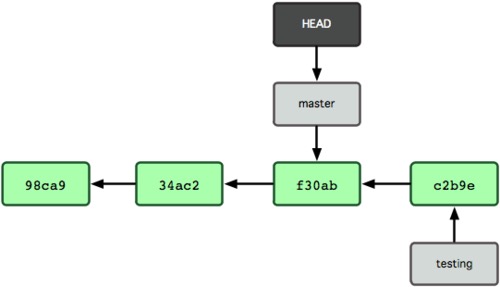
这条命令做了两件事:
我们试着在master上再做一些改动并commit:
1 | echo "testing master">>readme.txt |

现在分支变成了上图所示,我们可以在master与testing间随时切换,并修改工作区的文件内容。必要时再将这两个分支合并。
接下来,再以一个比较长的真实的工作场景进行举例
我们首先在master分支上进行工作,并提交了几次更新,测试无误后编译发布至生产系统。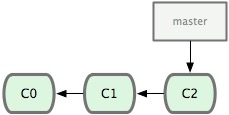
之后我们决定要修补问题追踪系统上的53号问题,这时可以使用git checkout -b命令快速创建一个分支并切换过去:
1 | $ git checkout -b iss53 |
这相当于执行了下面这两条命令:
1 | $ git branch iss53 |
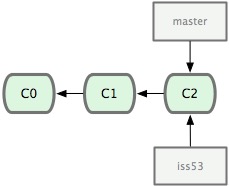
我们在iss53分支上写了一些代码,并commit
1 | $ vi index.html |
iss53上的工作还没完成,突然接到通知,生产系统有一个紧急BUG需要立刻修复。所以我们首先切回master分支,然后在master的基础上,又新建出一个hotfix分支来修复BUG。
1 | $ git checkout master #回到master分支 |
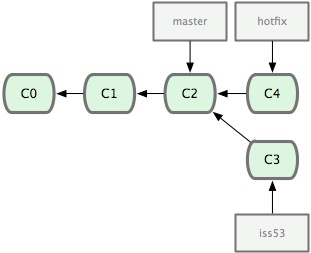
在hotfix分支上搞定BUG之后,我们切回master分支,使用git merge把刚才的hotfix合并进来
1 | $ git checkout master #切换回master分支 |

备注:本次合并时出现了“Fast forward”的提示。由于当前 master 分支所在的提交对象是要并入的 hotfix 分支的直接上游,Git 只需把 master 分支指针直接右移。换句话说,如果顺着一个分支走下去可以到达另一个分支的话,那么 Git在合并两者时,只会简单地把指针右移,因为这种单线的历史分支不存在任何需要解决的分歧,所以这种合并过程可以称为快进(Fast forward)。
这时hotfix分支已经没用了,可以删掉了
1 | $ git branch -d hotfix #只是删除了一个指针 |
现在回到之前未完成的53号问题上,继续写一些代码
1 | $ git checkout iss53 |

在问题53相关的工作完成之后,可以合并回master分支。实际操作同前面合并hotfix分支差不多,只需回到master分支,运行git merge命令指定要合并进来的分支。
1 | $ git checkout master |
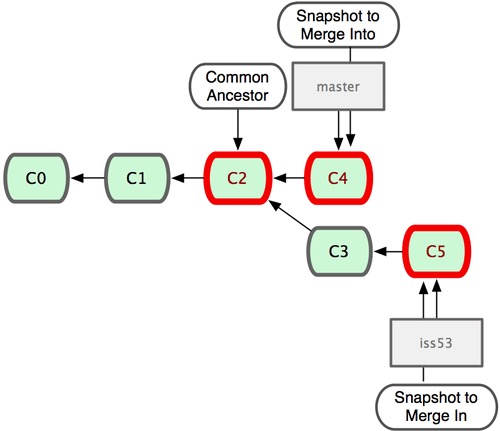
请注意,这次合并操作的底层实现,并不同于之前 hotfix 的并入方式。因为这次你的开发历史是从更早的地方开始分叉的。由于当前 master 分支所指向的提交对象(C4)并不是 iss53 分支的直接祖先,Git 不得不进行一些额外处理。就此例而言,Git 会用两个分支的末端(C4 和 C5)以及它们的共同祖先(C2)进行一次简单的三方合并计算。
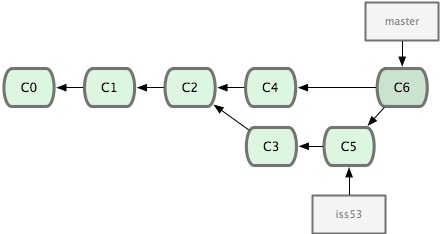
这次,Git 没有简单地把分支指针右移,而是对三方合并后的结果重新做一个新的快照,并自动创建一个指向它的提交对象(C6)。这个提交对象比较特殊,它有两个祖先(C4 和 C5)。
有时候合并操作并不会如此顺利。如果在不同的分支中都修改了同一个文件的同一部分,需要手工来处理冲突。
1 | $ git merge iss53 |
Git作了合并,但没有提交,它会停下来等你解决冲突。
1 | $ git status |
任何包含未解决冲突的文件都会以未合并(unmerged)的状态列出。Git 会在有冲突的文件里加入标准的冲突解决标记。
1 | $ vi index.html |
可以看到 ======= 隔开的上半部分是 HEAD,即master,下半部分是在iss53分支中的内容。
手工合并代码后,把 <<<<<<<,======= 和 >>>>>>> 这些行也一并删除。这时可以用git commit来提交了。
实际开发中,对于分支的管理,已经有很多最佳实践,大多数情况下,我们只需要遵守一些基本原则:
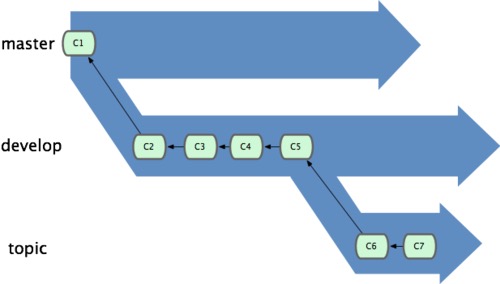
之前讨论过远程仓库,接着又学习了分支,当二者结合到一起时,又会产生一些有趣的东西。
远程分支(remote branch),即远程仓库中的分支。同步到本地后,与本地分支不同的是,它们 无法移动 ;且只有在Git进行网络交互时才会更新。远程分支就像是书签,提醒着你上次连接远程仓库时上面各分支的位置。我们用 (远程仓库名)/(分支名) 这样的形式表示远程分支(例如origin/master)。
如果我们在本地master分支做了些改动,与此同时,其他人向远程仓库推送了他们的更新,那么服务器上的master分支就会向前推进,而于此同时,我们在本地的提交历史正朝向不同方向发展。(不过只要你不和服务器通讯,你的 origin/master 指针仍然保持原位不会移动。)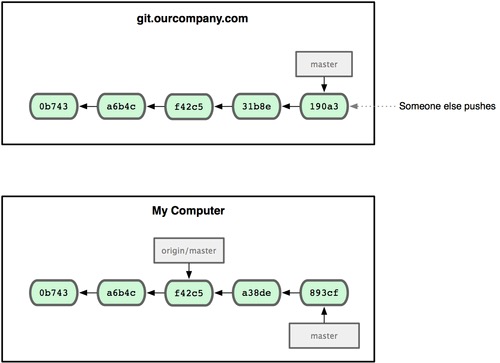
可以运行git fetch origin来同步远程服务器上的数据到本地。该命令首先找到origin是哪个服务器,然后从上面获取你尚未拥有的数据,更新你本地的数据库,然后把origin/master的指针移到它最新的位置上。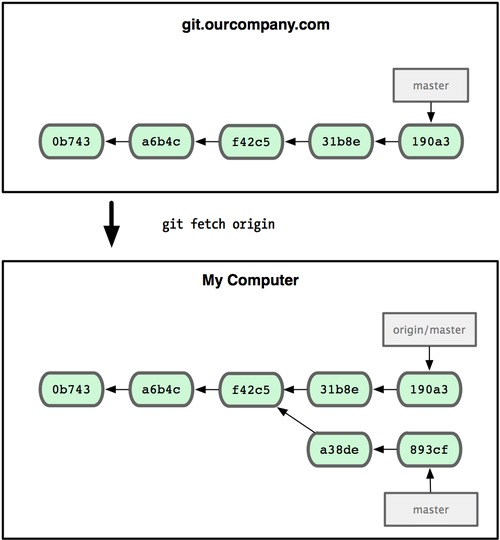
可以使用git remote命令查看远程仓库的详情
1 | $ git remote -v #列出远程服务器清单 |
从远程分支checkout出来的本地分支,称为跟踪分支 (tracking branch)。跟踪分支是一种和某个远程分支有直接联系的本地分支。
在跟踪分支里输入 git push,Git 会自行推断应该向哪个服务器的哪个分支推送数据。同样,在这些分支里运行 git pull 会获取所有远程索引,并把它们的数据都合并到本地分支中来。
在克隆仓库时,Git 通常会自动创建一个名为 master 的分支来跟踪 origin/master。这正是 git push 和 git pull 一开始就能正常工作的原因。
1 | $ git checkout -b serverfix origin/serverfix |
这会新建并切换到serverfix本地分支,其内容同远程分支origin/serverfix一致。
要想和其他人分享某个本地分支,你需要把它推送到一个你拥有写权限的远程仓库。
例如本地有一个serverfix分支需要和他人一起开发,可以运行 git push (远程仓库名) (分支名):
1 | $ git push origin serverfix |
或者加入–set-upstream设置跟踪后,以后直接使用git push就可以推送了:
1 | git push --set-upstream origin serverfix |
[GitHub](https://github.com)是一个面向开源及私有软件项目的托管平台,因为只支持Git作为唯一的版本库格式进行托管,故名GitHub。
GitHub本身没有什么好学的,随便看就知道怎么用了 知乎:怎样使用GitHub
重点是,GitHub上有非常多优秀的个人项目值得我们学习,我们也可以将自已的代码发布上去。可以看成是程序员的博客吧,只贴代码,不废话。
在GitHub上发布开源项目是免费的,但是私有项目收费。
GitLab是一个用Ruby on Rails写的开源的版本管理系统,实现一个自托管的Git项目仓库,可通过Web界面进行访问公开的或者私人项目。它拥有与Github类似的功能,能够浏览源代码,管理缺陷和注释。
可以管理团队对仓库的访问,它非常易于浏览提交过的版本并提供一个文件历史库。团队成员可以利用内置的简单聊天程序(Wall)进行交流。它还提供一个代码片段收集功能可以轻松实现代码复用,便于日后有需要的时候进行查找。
GitLab是目前搭建内部Git服务器的首选,当然如果要求不高的话,我们也可以直接使用SSH协议来快速搭建Git服务端。
更多内容请直接参考 阮一峰的网络日志
不要指忘2小时的培训能带来多大的收益,最简单高效的方式,还是要多看优秀的文档。
本文大量参(chao)考(xi)了以下两部文档:
廖雪峰的在线教程 适合快速上手
Pro Git中文版 中文第一版
起因是某个同事接到了领导安排下来的一个需求,要在一个Web应用(Java+Tomcat)中,记录用户登录时的IP地址和MAC地址,用于安全审计,于是咨询我如何实现。
第一反应是,这个需求本身是不成立的,根据以往的了解,MAC地址应该是过不了路由器的才对。
以往做开发,都是用engineer的思维:先动手做,遇到问题再解决问题。但这个需求,应当用scientist的思维去思考:首先确定能不能做,然后才是怎么做。
翻查了一些资料,想来证实”为什么WEB服务器,可以获取到客户端的IP地址,但获取不到MAC地址“,看着看着才发现,这是个挺大的命题,够写一篇BLOG了。
PS:由于个人对这块内容了解的不够彻底,本文很可能会有谬误,请读者先不要太当真,另外希望平台组的同事给予指证。
我所认为的结论应该是这样的:
下面一步步解释一下。
先从HTTP说起。
HTTP是一个应用层的协议,它建立在TCP协议之上。
HTTP请求就是用来发送一段文本。关于这段文本如何组织,第一行写什么,第二行写什么,哪里加一个空行,就是HTTP协议所要规范的内容。
举个直接的例子,下面是一个简单的HTTP GET请求,有兴趣可以用telnet模拟一下。
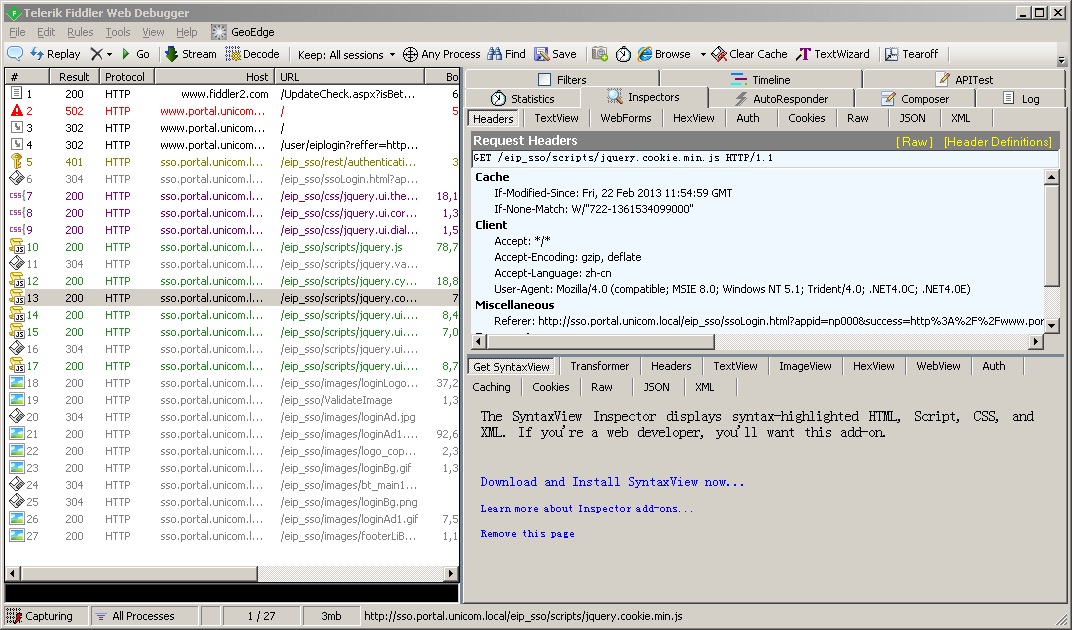
1 | GET http://www.fiddler2.com/UpdateCheck.aspx?isBeta=False HTTP/1.1 |
我们可以看到,HTTP的这段请求中,完全找不到客户端的MAC地址,甚至连IP地址都没有描述。
那IP地址是从哪里取到的呢?接下来我们再深入一点,看下一个内容:Socket
HTTP的客户端和服务端,是通过Socket进行连接的。
Socket是什么呢?Socket是对OSI模型第4层-传输层中的TCP/IP协议的封装。Socket本身并不是协议,而是一个调用接口(API)。Socket和TCP/IP协议没有必然的联系。但通过Socket,我们才能使用TCP/IP协议。应用层不必了解TCP/IP协议细节,直接通过对Socket接口函数的调用完成数据在IP网络的传输。
Socket包含了网络通信必须的五种信息:连接使用的协议,本地主机的IP地址,本地进程的协议端口,远地主机的IP地址,远地进程的协议端口。
所以,因为有了Socket,客户端和服务端完全不需要了解底层细节,直接通过调用Socket来实现就可以了。
这也就是为什么服务器端可以获取到客户端的IP地址的原因,因为Socket中包含了远地主机的IP地址。(当然,通过代理服务器进行访问的除外,这种要依靠HTTP协议的X-Forwarded-For头来确认IP,不在本次的讨论范围中)
那为什么无法获取到客户端的MAC地址呢?很简单,同理,因为Socket中无法取到MAC地址。。。
如果继续发问,为什么Socket中都既然都包含IP地址了,为什么偏偏不包含MAC地址信息呢?看来我们还要更深入一点,看一下OSI模型吧。
首先祭出这张经典的OSI七层模型图,计算机网络的基石,请先盯着看一会儿,认真复习一下
这里还有一张OSI七层模型与TCP/IP四层模型的对照图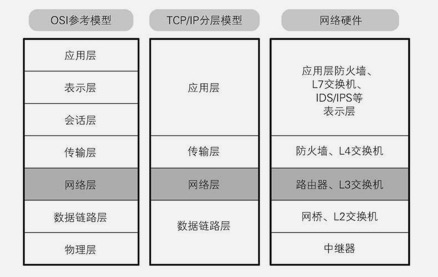
为了方便理解,再放上一张更直观的,每一层对应的数据型式和主要协议的示意图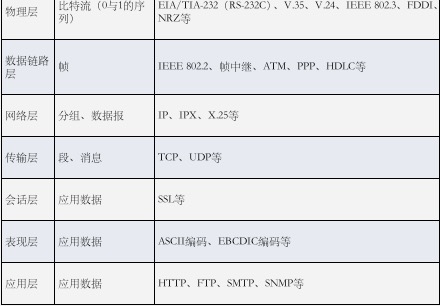
通过上图大体可以知道:
下面举个栗子,当我们在浏览器中打开一个链接后,看看OSI各层倒底发生了什么:
这里撇开DNS解析之类东西,只说一下HTTP报文的发送
首先来看一下发送端(浏览器所在的主机)。参照第一张OSI模型图,按照从上向下的顺序来看。应用层数据其实只有那么几行文本,然后往下,每过一层,都要被加上首部/尾部。这个过程就像是一层一层的穿衣服。
HTTP请求文本:
最后到了数据链路层之后,数据就变成了这个肥肥的样子,最后转换成0和1的电信号发出:
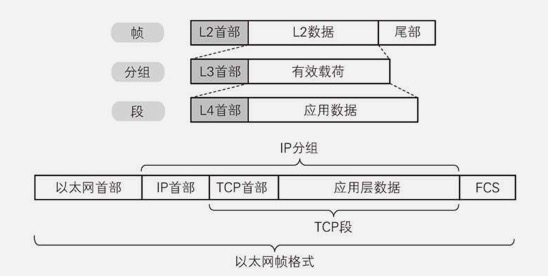
下面看看,现实中,每一层都做了些什么(现实中的分层和OSI模型还是有区别的):
第7,6,5层,也就是OSI中的应用层,表示层,会话层(也是TCP/IP分层中的应用层),它创建了一个HTTP请求(例如 GET / HTTP/1.1),并交给下一层。一个普通的HTTP GET请求就是几行纯文本。
处理这三层,是浏览器和WEB服务器所要做的工作,浏览器发出请求,WEB服务器做出响应。
第4,3层,也就是传输层/网络层。TCP/IP栈将上层的数据分成包(packets),并将它送往下一层-数据链路层。
IP地址、端口号记录在这两层中。
处理这两层,是操作系统要做的工作,操作系统将这两层封装为了Socket,方便调用。
MAC地址记录在这一层中。
这一层的工作,交由网卡来处理。
数据发出去后,再看一下数据在网络上的流转。
数据一般要经过交换机、路由器等网络设备,层层转发,这些设备所做的事情就像是: 脱掉一件或几件衣服,做一些修修补补,然后再重新穿回去。

通过上面这张图,我们就可以理解,MAC地址在本地网络下的重要作用了。也理解了,本地网络下,是可以查出每个节点的MAC地址的。

经过路由器后,为了能到达下一跳,数据链路层中的MAC地址就被篡改了,下面这张图很能说明问题:
最后看一下接收端(WEB服务器所在的主机)。参照第一张OSI模型图,按照从下至上的顺序来看,它要做的事情是: 将衣服一件一件全部脱掉 ,最后WEB服务器就取到了最初的应用层数据。
所以,当一个以太网帧到达目的主机后,其中的MAC地址早已经不是原来客户端的MAC了,操作系统的Socket自然也无法获取原始的MAC地址了。
上面已经证明了,WEB服务端,是无法获取客户端的MAC地址的。
那么,能不能通过一些trick来绕道实现呢?
想了想,大概可以有如下的思路:
那么这个思路可不可行呢?
最后的最后,不禁思考,获取MAC的意义在哪里呢?
如果单纯是为了取证和审计,我想意义是不大的,甚至不如直接记录IP地址。
因为:
所以,一般的安全管控要求下,还是只记录IP吧。

简单来说,IntelliJ Idea是目前最好的Java集成开发环境,没有之一。
Java应该是非常依赖IDE的一门语言了,恐怕也没有几个大牛能够直接用Vim/Emacs愉快的手撸代码,Java程序员离开了IDE基本上生活不能自理,IDE的重要性不言而喻。
最近在推行、部署各种自动化工具,但个人认为,相比于各种工具,一个好的IDE更是能 极大的提升 工作效率以及编码的爽快感。
目前团队中使用的开发工具主要还是Eclipse和NetBeans,所以就想借这篇文章安利一下,希望团队中更多的人能开始尝试并喜欢上IntelliJ IDEA。
目前常用的IDE主要有3个:
其中,Eclipse及其衍生品是最为我们所熟知的,Eclipse开源,历史悠久,插件丰富,对一些老项目兼容性也比较好,另外有很多基于Eclipse的项目也很流行,比如STS、MyEclipse。
NetBeans使用的人稍微少一些,但它有很多比Eclipse更为优秀的地方,例如免费、Oracle自家出品,对于新标准的支持非常好、有中文语言包、界面布局更合理等。
但从目前的统计数据来看,IntelliJ Idea的市场份额已经超过了Eclipse。
IntelliJ IDEA作为一个商业化的IDE,而且是一个非常昂贵的商业化IDE(499刀/年),能够被如此多的开发人员认可,肯定有它非凡之处,简单罗列几点:
要想开始体验IntelliJ IDEA,首先要新建一个工程(Project)或导入已有的工程。这里我们选择从版本库中导入一个已有的工程。
在欢迎界面中点击最下方的 Check out from Version Control
可以看到,IntelliJ IDEA支持GitHub、CVS、Git、Svn等多种版本库。
这里我们尝试导入一个GitHub中的工程,填写自已的GitHub用户名、密码
在下拉列表中选择好一个工程后,点击 Clone
如果项目是用Gradle/Maven构建的,还会弹出一个构建工具配置界面
导入完成后,可以看到主界面了
IntelliJ IDEA中的项目结构和Eclipse有很大的不同。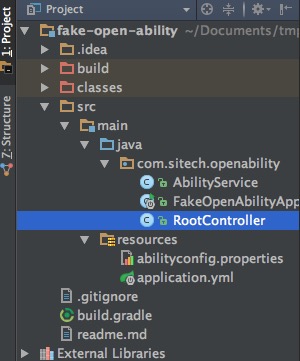
界面左侧的Project栏,可以查看项目中的文件结构,通过Cmd+1快捷键调出/关闭。
使用Cmd+; 快捷键,可以打开项目设置界面,在这里配置模块、库、Facets、Artifacts等。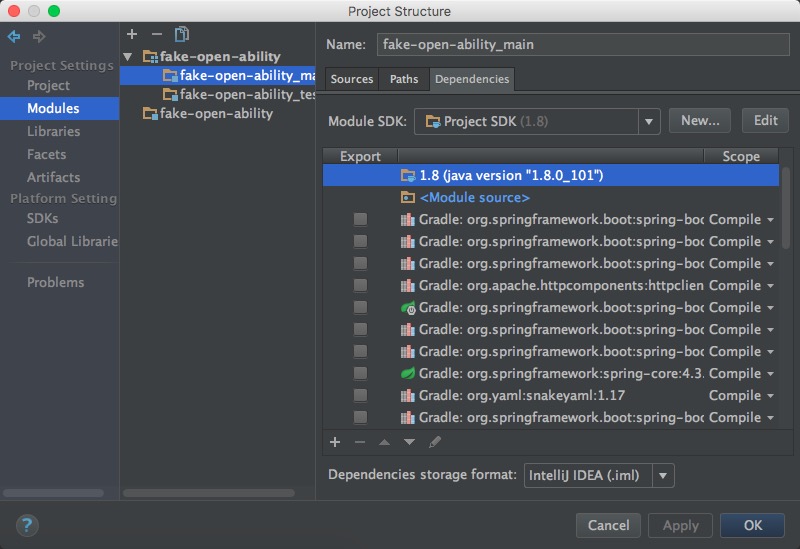
Facets可以认为是项目支持的特性,例如JPA、Spring、Hibernate等,当一个项目被IDEA扫描完毕之后,它会自动为每个模块添加相应用Facets,当然也可以手工进行添加
Artifacts是项目的打包部署设置。
例如,对于WEB工程而言,IDEA通过配置Artifacts,将编译输出的class文件,与jsp/html/css页面等静态文件,以特定的目录结构合并到一起。
点击Project栏中右上角齿轮图标,可以调整目录的展示方式,比如合并中间空目录等:
下面是一份Eclipse与IntelliJ IDEA的快捷键比对表: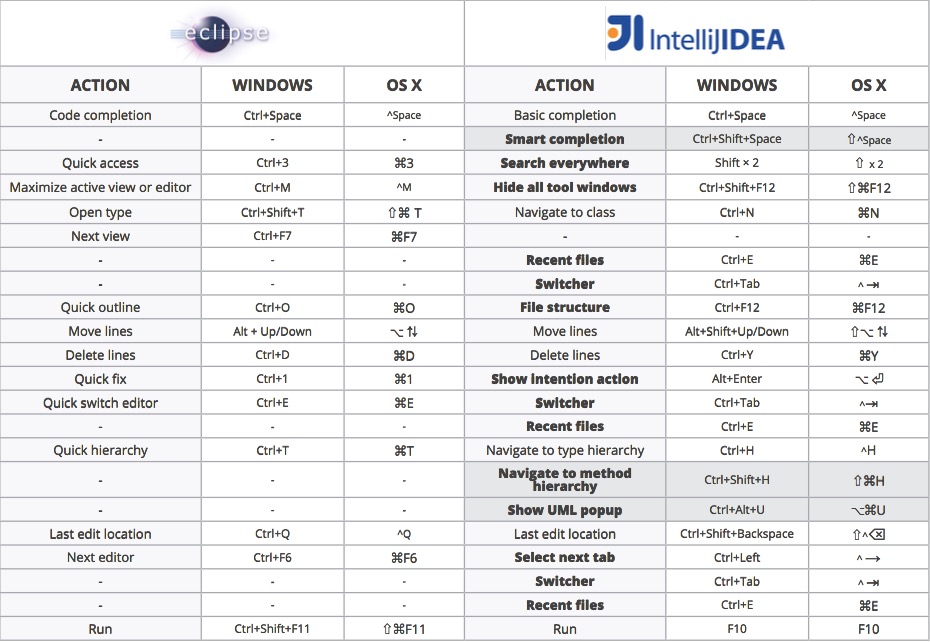
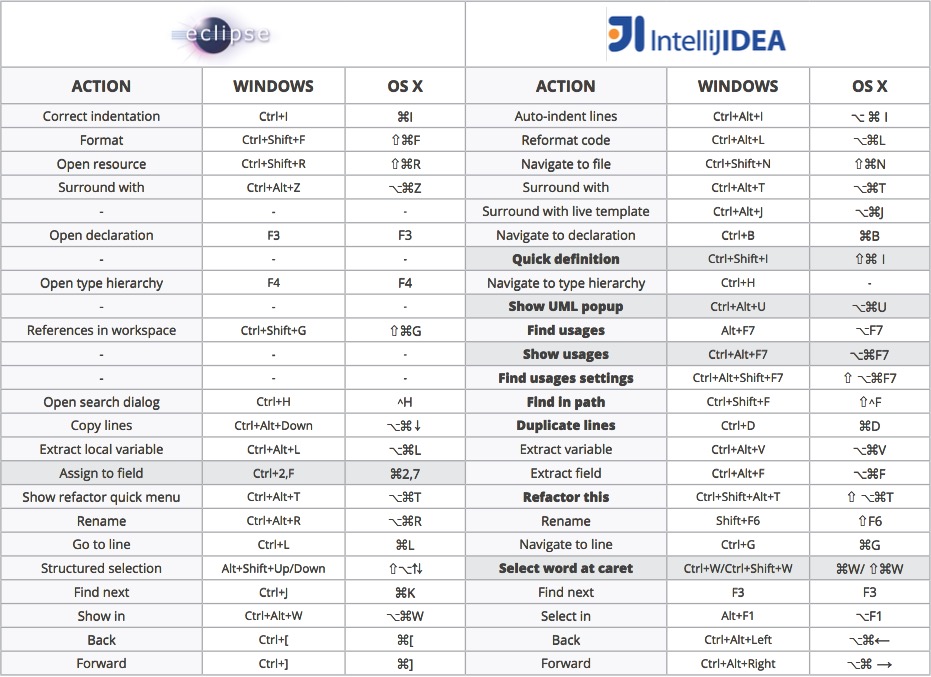
如果不想使用IDEA的默认快捷键,想沿用之前的一些习惯,IDEA也提供了几套其它的配置,使用 Ctrl+` 调出菜单
选择 3-Keymap 即可切换配置
但建议还是尽量适应IntelliJ IDEA的默认快捷键配置吧。
下面有几个有趣的与其它IDE的区别:
Cmd+DCmd+D是删除一行,但在IntelliJ IDEA中,D是指duplicate,复制一行。 Cmd+SCmd+S只能给我们带来一些心理上的”安全感”。 IntelliJ IDEA的默认布局非常的简洁,几乎只有一个编辑器界面,甚至还可以通过Ctrl+Cmd+F全屏显示,以获得更加沉浸式的体验。
点击界面最左下角的显示器形状的图标,可以用来切换布局模式,调出或隐藏周边的工具栏
在使用精简布局时,如果要进行文件定位、打开某个侧边栏等操作,就需要使用一些快捷建进行操作了。
一般是使用Cmd+数字来显示侧边栏,例如Cmd+1显示Project栏,Cmd+9显示版本控制栏,具体数字界面上会有提示。
另外,Cmd+E不但可以显示最近使用过的文件,还可以在左侧选择打开各个侧边栏,非常好用。
同样的,Ctrl+Tab快捷键可以实现类似的功能,并且效率更高
使用Cmd+O可以弹出快速 查找类名 窗口,输入类名关键字筛选,可以快速打开类所在的源文件
使用Cmd+Shift+O可以弹出快速 查找文件名 窗口,输入文件名关键字,可以打开任意文件
还有一个更方便的方式,如果不确定要找什么,双击shift键,可以弹出”Search Everywhere”窗口,输入关键词搜索一切吧。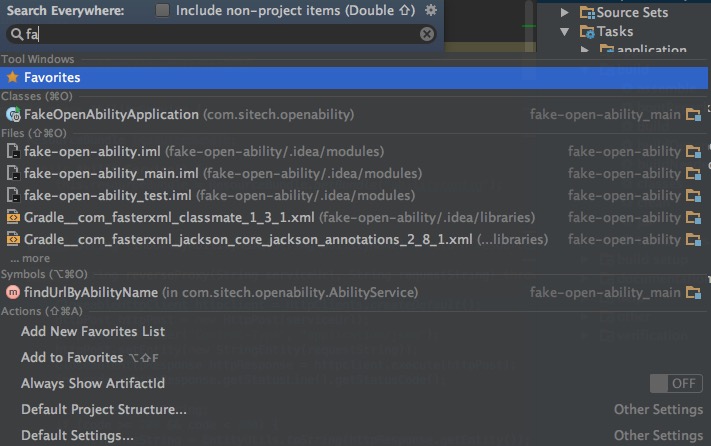
当然,还可以使用之前提到过的Cmd+E,查看曾经打开过的文件。
使用空格与TAB键缩进,在码农界争论至今还没有定论,那就不妨根据自已的喜好手工设置一下吧。
首先使用Cmd+,打开全局设置界面,在Editor → Editor Tabs中可以找到相应的选项: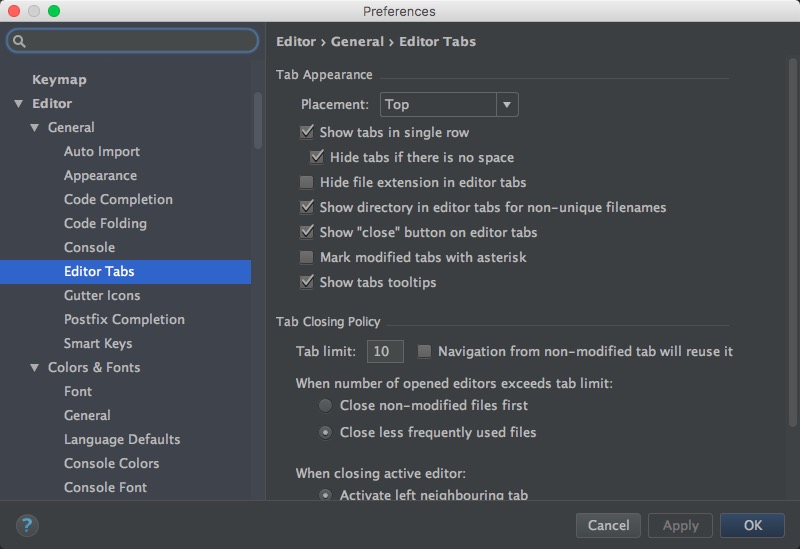
在Appearance & Behavior → Appearance中,可以设置喜欢的主题,字体、字号等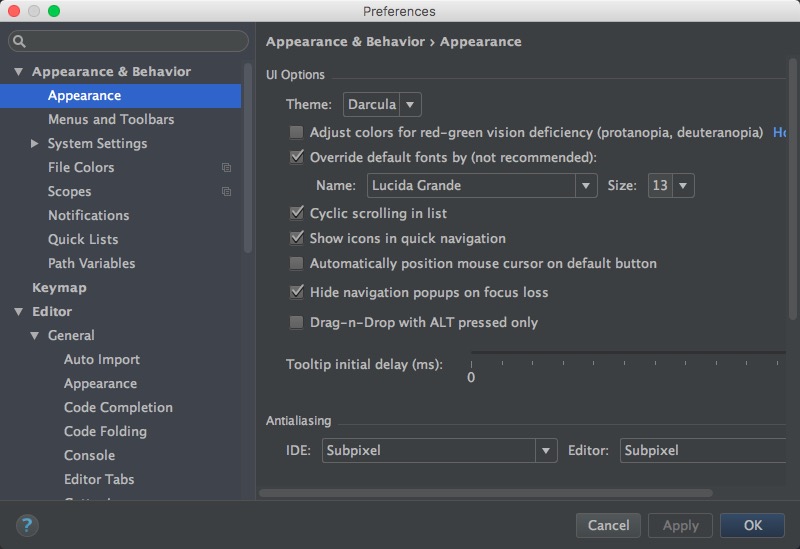
这里当然是首推Darcula主题。
首先要记忆的一个快捷键是Cmd+F12,可以打开 class outline 窗口,查看文件中的各个方法。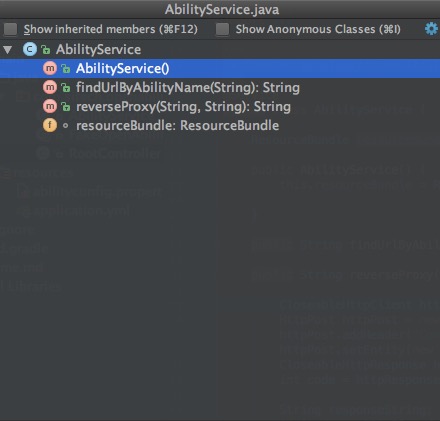
类似的也可以通过Ctrl+H打开 type hierarchy 侧边栏
另外,还可以使用Alt+F7,打开 Find Usages 底边栏,显示方法的使用者。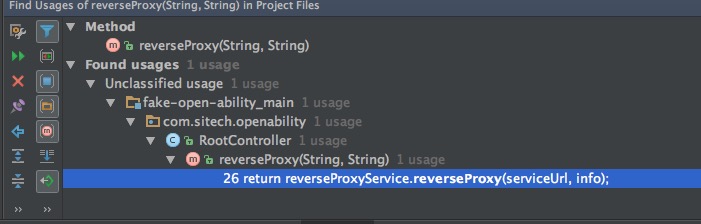
使用Ctrl+Space,可以进行代码自动补全。
Ctrl+Shift+Space,是更加智能的代码补全,它会猜测你的意图,只展示最有用的结果
另外Alt+Enter也十分有用,当使用了一个类,但它还没有被导入时,可以用它来快速导入
使用Cmd+N可以自动生成代码,比如Getter/Setter/toString()等等
最简单的,可以通过右键菜单或Shift+F6进行重命名,可以是文件,也可以是类名、方法名、变量名等,点击确认后IntelliJ IDEA会跨语言检索全部代码(包括.html/.js),找到所有相关的地方一起修改。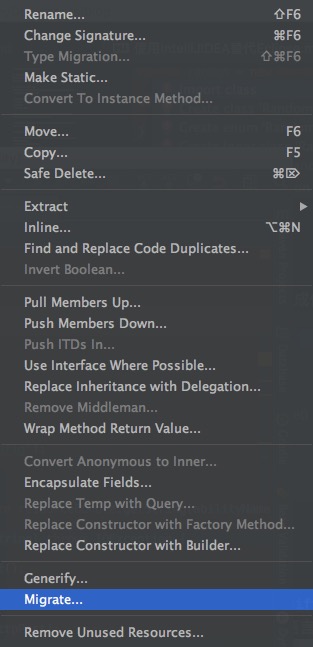
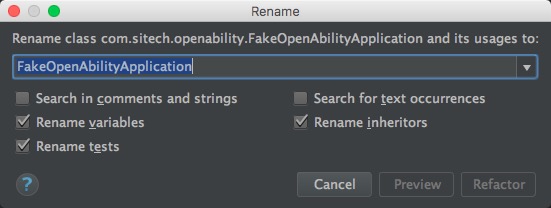
输入特定的关键字,按TAB后,可以直接在光标处插入模板代码。
例如,首先输入psvm
然后按下TAB键,就会自动插入一个main方法的模版,相当快捷
Cmd+Alt+LCmd+F9Shift+ESC到现在为止,已经接触了IntelliJ IDEA的不少快捷键了。
其实对于学习一个文本编辑器也好、IDE也好,要想用的得心应手,记忆大量的快捷键都是少不了的步骤。
但如果记不清快捷键怎么办,去哪里查呢?幸好IntelliJ IDEA为我们提供了一个终级快捷键 Cmd+Shift+A,这是一个用来 查找快捷键的快捷键 !其它所有的快捷键都忘了也没有关系,只要记得这一个。。。

对于Web应用,如果想在本机直接运行测试,除了使用Maven等构建工具内嵌的Application Server之外,还可以选择直接在IntelliJ中配置一个。
注意请提前配置好Artifacts,然后点击顶部右侧的 Run Configuration 按钮,在新窗口中点击左上角加号,选择Tomcat即可: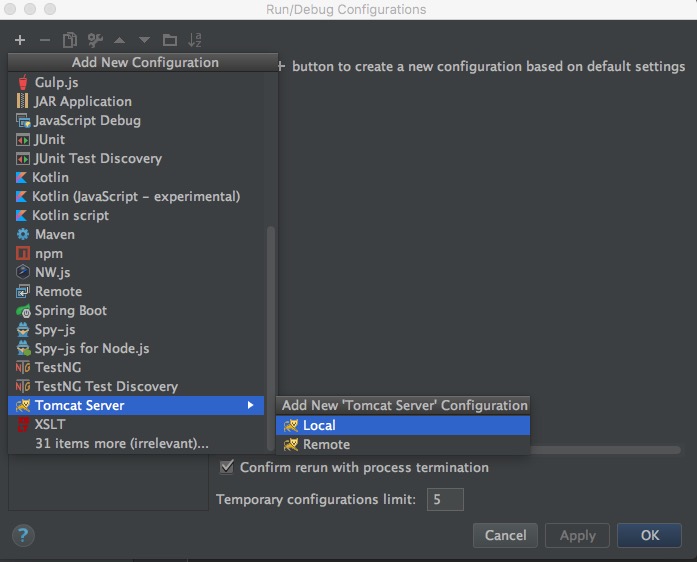
在向版本库中提交时,可以在右侧选择进行一些提交前的处理,如代码检查、格式化等:
在Tab页上点击右键,可以选择Add to Favorites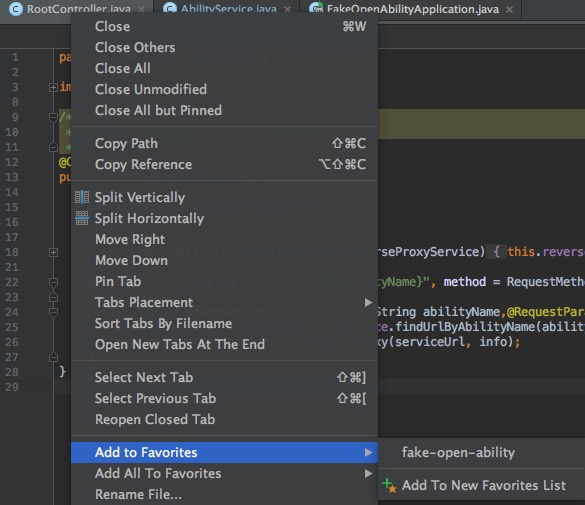
然后在左下方的Favorites栏中就可以看到了
在窗口左下方的 Version Control 栏中,可以查看到做过变更的文件
在文件上右键,可以进行代码差异比对,回滚等操作
在窗口右上方的工具栏中,可以快速Update/Commit
在窗口右下方的工具栏中,可以查看/新建/切换Git分支
菜单栏中,Tools一项中,可以找到很多内嵌的工具,比如很常用的Rest测试工具
在右侧的Database工具栏中,可以配置常用的数据源
配置好之后,就可以使用内嵌的数据库查询管理工具了,另外在编写配置文件或SQL/JPQL时,也会有对应用智能提示
以上介绍的,只是IntelliJ IDEA众多功能中的冰山一角,想要了解更多,请进一步参考官方文档:
另外官网上也提供了很多的视频教程,其中有不少小技巧。
最近厂里有一个新闻采集类的需求,细节大体如下:
初学Python3,正好用这个需求练练手,最后很惊讶的是只用200多行代码就实现了,如果换成Java的话大概需要1200行吧。果然应了那句老话:人生苦短,我用Python
第一步当然是抓包,然后再根据抓到的内容,模拟进行HTTP请求。
常用的抓包工具,有Mac下的Charles和Windows下的Fiddler。
它们的原理都是在本机开一个HTTP或SOCKS代理服务器端口,然后将浏览器的代理服务器设置成这个端口,这样浏览器中所有的HTTP请求都会先经过抓包工具记录下来了。
Chrales
https://www.charlesproxy.com
这里推荐尽量使用Fiddler,原因是Charles对于cookie的展示是有bug的,举个例子,真实情况:请求A返回了LtpaToken这个cookie,请求B中返回了sid这个cookie。但在Charles中的展示是:请求A中已经同时返回了LtpaToken和sid两个cookie,这就很容易误导人了。
另外Fiddler现在已经有了Linux的Beta版本,貌似是用类似wine的方式实现的。
如果网站使用了单点登录,可能会涉及到手工生成cookie。所以不仅需要分析每一条HTTP请求的request和response,以及带回来的cookie,还要对页面中的javascript进行分析,看一下是如何生成cookie的。
将页面分析完毕之后,就可以进行模拟HTTP请求了。
这里有两个非常好用的第三方库, request 和 BeautifulSoup
requests 库是用来代替urllib的,可以非常人性化的的生成HTTP请求,模拟session以及伪造cookie更是方便。
BeautifulSoup 用来代替re模块,进行HTML内容解析,可以用tag, class, id来定位想要提取的内容,也支持正则表达式等。
具体的使用方式直接看官方文档就可以了,写的非常详细,这里直接给出地址:
requests官方文档
BeautifulSoup官方文档
通过pip3来安装这两个模块:
1 | sudo apt-get install python3-pip |
导入模块:
1 | import requests |
模拟登录:
1 | def sso_login(): |
这里用到了BeautifulSoup进行HTML解析,取出页面中的token、ltpa等字段。
然后使用session.cookies.set伪造了一个cookie,注意其中的domain参数,设置成1级域名。
然后用这个session,去调用网站页面,换回sid这个token。并可以根据页面的返回信息,来简单判断一下成功还是失败。
登录成功之后,接下来的列表页面抓取就要简单的多了,不考虑分页的话,直接取一个list出来遍历即可。
1 | def capture_list(list_url): |
这里使用了response.encoding = "UTF-8"来手工解决乱码问题。
新闻页面抓取,涉及到插临时表,这里没有使用每三方库,直接用SQL方式插入。
其中涉及到样式处理与图片转存,另写一个模块pconvert来实现。
1 | def capture_content(news_cid): |
文本样式处理,还是要用到BeautifulSoup,因为原始站点上的新闻内容样式是五花八门的,根据实际情况,一边写一个test函数来生成文本,一边在浏览器上慢慢调试。
1 | def convert_style(rawtext): |
因为原始站点是在内网中的,采集下来的HTML中,标签的地址是内网地址,所以在公网中是展现不出来的,需要将图片转存,并用新的URL替换原有的URL。
1 | def convert_img(rawtext): |
图片转存最简单的方式是保存成本地的文件,然后再通过nginx或httpd服务将图片开放出去:
1 | pic_name = raw_img_url.split('/')[-1] |
但这里我们需要复用已有的FastDFS分布式文件系统,要用到它的一个客户端的库fdfs_client-py
fdfs_client-py不能直接使用pip3安装,需要直接使用一个python3版的源码,并手工修改其中代码。操作过程如下:
1 | git clone https://github.com/jefforeilly/fdfs_client-py.git |
客户端的使用上没有什么特别的,直接调用upload_by_buffer,传一个图片的buffer进去就可以了,成功后会返回自动生成的文件名。
1 | from fdfs_client.client import * |
其中dfs.conf文件中,主要就是配置一下 tracker_server
这里使用配置文件的方式处理日志,类似JAVA中的log4j吧,首先新建一个log.conf:
1 | [loggers] |
这里通过配置handlers,可以同时将日志打印到stderr和文件。
注意args=('logs/pspider.log','a','utf8') 这一行,用来解决文本文件中的中文乱码问题。
日志初始化:
1 | import logging |
日志打印:
1 | logging.info("test") |
到此为止,就是如何用Python3写一个爬虫的全部过程了。
采集不同的站点,肯定是要有不同的处理,但方法都是大同小异。
最后,将源码做了部分裁剪,分享在了GitHub上。
https://github.com/xiiiblue/pspider
最后,将源码做了部分裁剪,分享在了GitLab上。
http://git.si-tech.com.cn/guolei/pspider