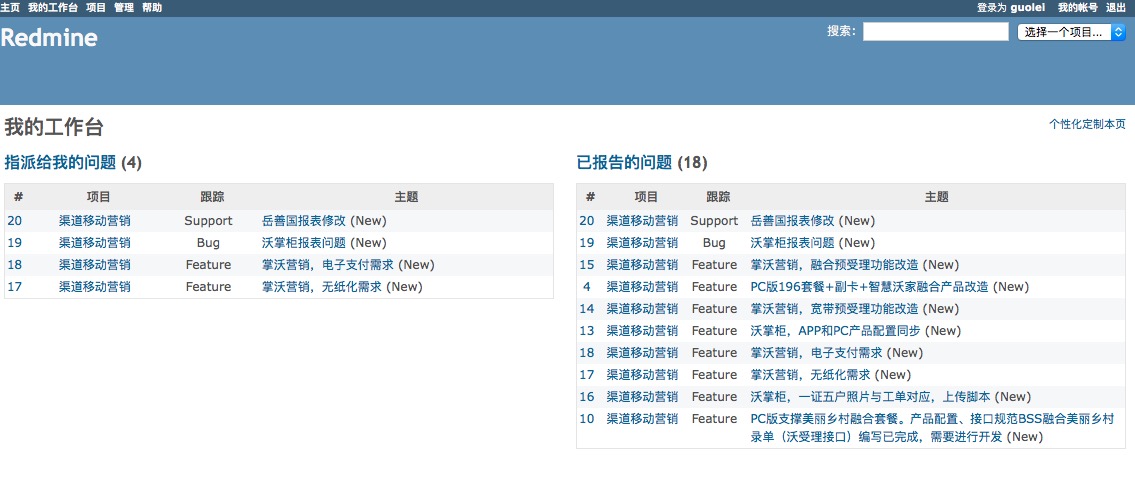
引子
SSH连接是我们与服务器交互的主要手段,每个程序员每天都会用到,就像喝白开水一样普通。
就是这样一个简单而又高频的动作,如果配置得当,或许能极大的提高我们工作的幸福感吧。
前不久一个同事刚从Windows切换到macOS平台,问我SecureCRT有没有mac下的版本,我说即然都用上了基于BSD的mac了,应该不再需要SecureCRT这样的东西了才对,SSH如果配置好了,体验应该完爆Windows。于是就有了写下这篇文章的念头,填一下之前的坑。
选择终端GUI工具
首先第一步是选择一个好用的GUI工具,毕竟大多数人都是在DE下工作,极少人会喜欢工作在tty1这样的文字介面下。
Windows平台
Windows平台下的工具比较多,下面捡几个主要的来说一说优缺点:
- SecureCRT - 老牌的商业软件,同时也提供Mac和Linux版本,功能强大,费用昂贵,但貌似身边所有人都在用盗版,PASS
- Xshell - 有免费的License,但只允许非商业场景下使用,这个也PASS
- Putty - 好吧,只能是它了,免费,功能简单,但是也足够用了
- Cygwin - 差点把这个忘了,严格来说它并不仅仅是一个SSH工具,也值得推荐
macOS平台
macOS平台的终端工具比较好选,公认的只有iTerm2一个:
- 原生Terminal - 开箱即用,功能上也不过不失,但抛弃它,只是因为有更好的iTerm2。。。
- iTerm2 - 免费,支持众多的自定义选项,可以完全替代原生Terminal,没得选,就是它了
Ubuntu平台
Ubuntu默认自带一个gnome-terminal,虽然不像iTerm2那样讨喜,但胜在简洁,个人认为是最优的选择吧:
- Terminator - 支持窗口拆分,但界面丑,不能忍,PASS
- Guake - 支持下拉式的呼出,但界面更丑,PASS
- 原生Terminal - 界面简洁,功能够用,最终还是用回了它
iTerm2使用简介
Putty和gnome-terminal的配置都比较简单,记住几个快捷键就可以了,macOS下的iTerm2配置和使用都要麻烦些,这里单独拿出来写一下。
配置呼出快捷键
使用Cmd+,打开设置界面,切换到Keys一栏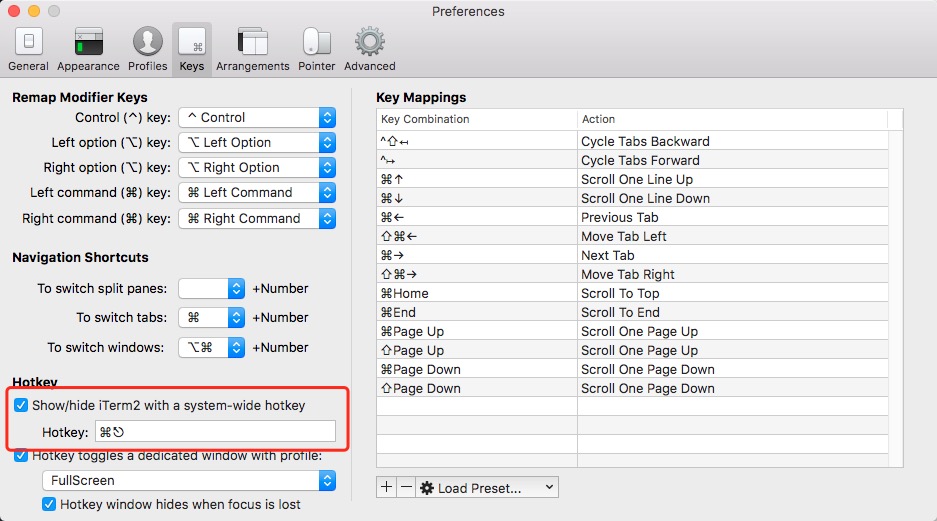
在左下方可以设置 呼出/隐藏 iTerm2的快捷键,这里我设置成了Cmd+ESC,瞬间呼出,比Alfred/Spotlight还要方便。
另外还可以在Profile一栏中修改窗口为全屏+半透明,完美。
选中即复制
使用鼠标选中一段文字后,默认就已经复制到剪贴板了,直接用Cmd+V粘帖即可。
Profile设置
使用Cmd+,打开设置界面,切换到Profile一栏
在这里可以配置远程服务器的连接参数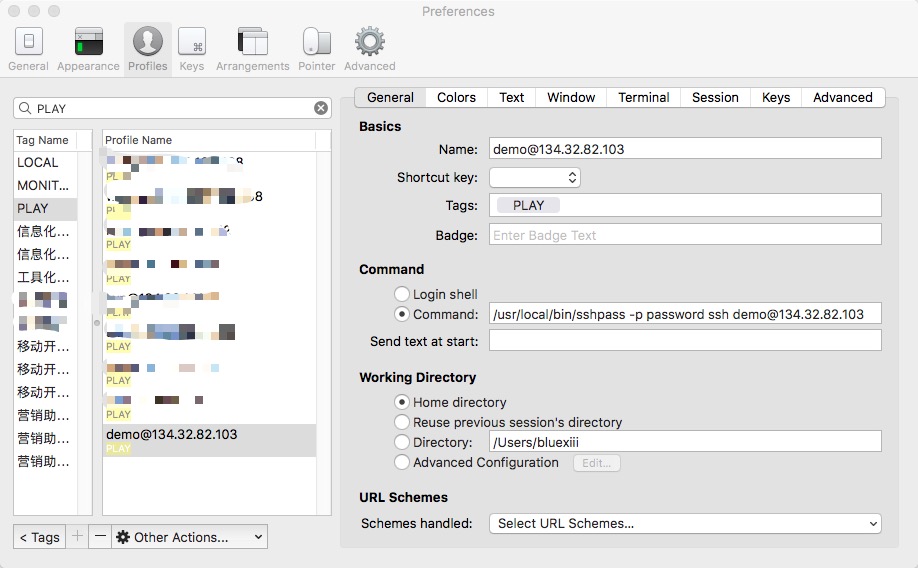
配合sshpass这个命令,可以实现类似SecureCRT的Session管理的功能。
注意,sshpass直接使用明文保存密码(SecureCRT是加密后存在本地),已经不推荐使用,下面会介绍一个更好的方式。
分屏
分屏功能相当好用,例如我们可以在屏幕左侧查看日志,右侧进行常规操作Cmd+D 垂直分割Cmd+Shift+D 水平分割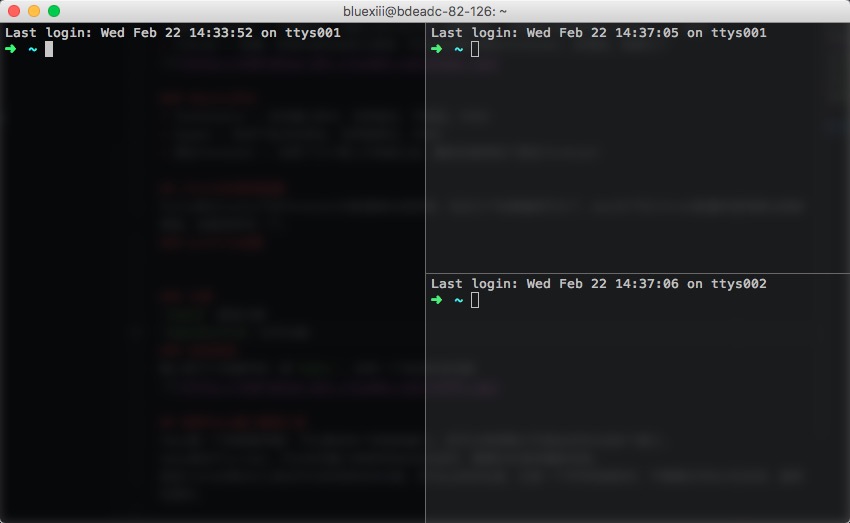
自动完成
输入前几个关键字后,按Cmd+;,会有一个自动补全功能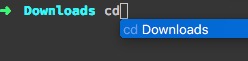
命令历史记录
使用Cmd+shift+H可以打开命令历史记录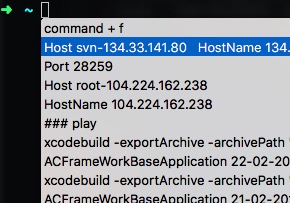
使用Tmux窗口管理工具
GUI工具有了,我们还缺一个通用的窗口管理工具–Tmux。
Tmux是一个终端复用器,它可以激活多个终端或窗口, 还可以将屏幕水平或纵向切分成多个窗口。
类似于screen,它可以关闭窗口将程序放在后台运行,需要的时候再重新连接。
其实iTerm2等GUI工具也可以实现类似的功能,但Tmux的好处是:
- 它是一个字符终端软件,不需要任何GUI的支持,通用性更好
- tmux可以 保持多个会话 ,只要不关机,就可以随时恢复Session
macOS下的安装
1 | brew install tmux |
Ubuntu下的安装
1 | sudo apt-get install tmux |
tmux的主要元素分为三层:
- Session 一组窗口的集合,通常用来概括同一个任务
- Window 单个可见窗口,和ITerm2中的Tab类似
- Pane 窗格,被划分成小块的窗口
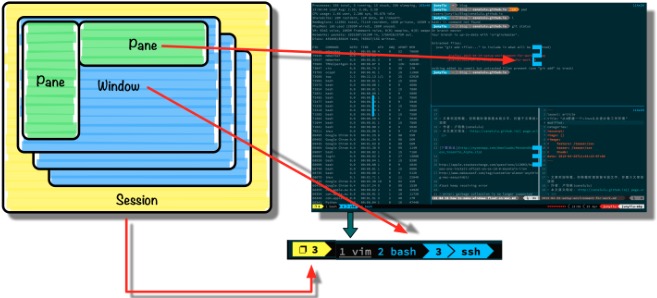
tmux默认的前置操作是CTRL+b。例如,我们想要新建一个窗体,就需要先在键盘上摁下CTRL+b,松开后再摁下n键。
下面所有的prefix均代表CTRL+b
- 查看/切换session
prefix s - 离开Session
prefix d - 重命名当前Session
prefix $
- 新建窗口
prefix c - 切换到上一个活动的窗口
prefix space - 关闭一个窗口
prefix & - 使用窗口号切换
prefix 窗口号
- 切换到下一个窗格
prefix o - 查看所有窗格的编号
prefix q - 垂直拆分出一个新窗格
prefix “ - 水平拆分出一个新窗格
prefix % - 暂时把一个窗体放到最大
prefix z
使用oh my zsh
工具已经齐全,但攘外必先安内,在连接远程服务器之前,我们先优化一下本机的Shell。
Linux系统中已经内置了几种shell,一般默认的是bash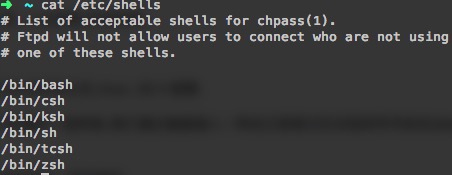
zsh比bash更加好用,且完全兼容bash,但它配置繁琐。幸亏有了oh-my-zsh,让zsh的配置难度大大降低。
首先安装一下zsh,mac系统无需安装,Ubuntu可以通过apt安装
1 | sudo apt install zsh |
根据官网的介绍,安装相当的简单,只需要一行命令即可
1 | $ sh -c "$(curl -fsSL https://raw.github.com/robbyrussell/oh-my-zsh/master/tools/install.sh)" |
zsh的配置文件是~/.zshrc,各项配置都有对应的注释,非常清晰,在这里可以修改主题,其实默认的已经很好看了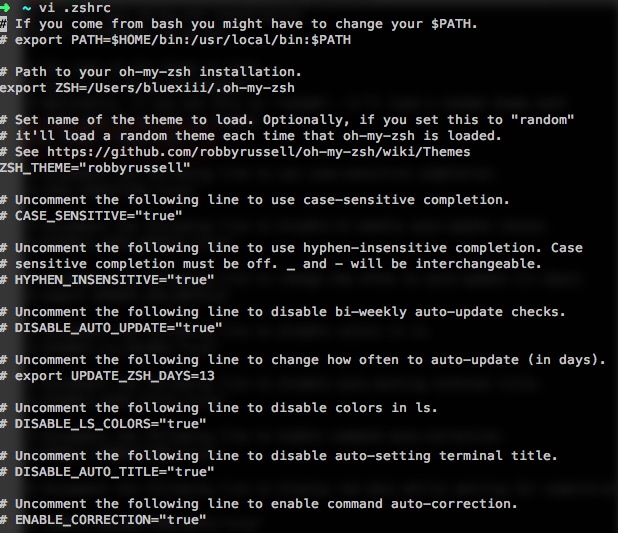
以下是zsh的一些使用技巧,请尽量记住,因为都很常用:
- 连按两次Tab会列出所有的补全列表并直接开始选择,补全项可以使用 ctrl+n/p/f/b上下左右切换
- 命令选项补全。在zsh中只需要键入 tar -
就会列出所有的选项和帮助说明 - 命令参数补全。键入 kill
就会列出所有的进程名和对应的进程号 - 更智能的历史命令。在用或者方向上键查找历史命令时,zsh支持限制查找。比如,输入ls,然后再按方向上键,则只会查找用过的ls命令。而此时使用则会仍然按之前的方式查找,忽略 ls
- 智能跳转,安装了 autojump 之后,zsh 会自动记录你访问过的目录,通过
j 目录名可以直接进行目录跳转,而且目录名支持模糊匹配和自动补全,例如你访问过 hadoop-1.0.0 目录,输入j hado即可正确跳转。j --stat可以看你的历史路径库。 - 目录浏览和跳转:输入
d,即可列出你在这个会话里访问的目录列表,输入列表前的序号,即可直接跳转。 - 在当前目录下输入
..或...,或直接输入当前目录名都可以跳转,你甚至不再需要输入cd命令了。在你知道路径的情况下,比如 /usr/local/bin 你可以输入cd /u/l/b然后按进行补全快速输入 - 通配符搜索:
ls -l **/*.sh,可以递归显示当前目录下的 shell 文件,文件少时可以代替 find。使用**/来递归搜索 - 扩展环境变量,输入环境变量然后按 就可以转换成表达的值
使用config记录远程连接
现在开始,我们再看一下如何连接远程服务器。
如果要管理几十台至上百台的主机,那么有没有什么方法能实现类似SecureCRT中Session管理那样的功能呢?
最简单的是使用iTerm2中的profile功能,它可以配置多台主机的连接,并可以使用tag进行归类。
但这种方式首先太依赖于GUI工具,离开了iTerm2就完全用不了。
其次是通用性不够好,配置文件不能跨平台,我们辛辛苦苦在Mac上配好了一份主机清单,但回家扔到Ubuntu下就没法用了。
有没有一种更为通用的方法呢?答案是直接使用openssh自带的config功能
配置文件的路径是:~/.ssh/config,如果不存在,可以新建一个
内容非常简单
1 | Host demohost |
第一行Host后面,可以为这个连接起一个简单的名字
后面几行记得缩进,HostName后面是IP地址,User后面是用户名,这两项是必填的。如果端口不是标准的22,还可以用Port指定端口。
配置好后,我们只需要输入ssh demohost,即可快速打开SSH连接了。
如果记不清连接名也没有关系,利用zsh的自动补全功能,输入ssh 关键字,再按一下TAB键,会列出所有包含关键字的连接,使用方向键选择后,回车确认即可。
使用ssh-copy-id免密码登录
接着再看一下,如何实现免密码登录远程主机。
之前我们提到过使用sshpass这个工具,可以直接将密码写进命令行中,从而实现非交互式的免密码登录
1 | sshpass -p password ssh demouser@92.168.1.1 |
但这种方式使用明文保存密码,非常不安全,不建议使用。
其实还有一种更好更直接的方式,那就是使用ssh-copy-id建立ssh信任关系,从而免密码登录。
首先,在本地机器上使用ssh-keygen产生公钥私钥对
1
ssh-keygen
一路回车即可,会在
~/.ssh目录下生成公钥私钥对。此命令只需执行一次即可。然后,用ssh-copy-id将公钥复制到远程机器中
1
ssh-copy-id -i demouser@192.168.1.1
按提示输入一次密码,ssh-copy-id就会自动将刚才生成的公钥
id_rsa.pub追加到远程主机的~/.ssh/authorized_keys后面了,以后的 ssh 以及 sftp 连接,都不用输入密码了。
至此,我们只要输入ssh demouser或sftp demouser,回车,就可以直接登录远程主机了。
安利一个小工具
最后的最后,再介绍一个很恶搞,但相当有用的小工具,thefuck GitHub页面
当我们敲错了命令,比如忘记加sudo时,只需要输入fuck并大力敲下回车,它就会非常智能的帮助我们更正了,非常有趣。
1 | ➜ apt-get install vim |
参考文档
http://cenalulu.github.io/linux/tmux/
http://harttle.com/2015/11/06/tmux-startup.html
http://wulfric.me/2015/08/iterm2/
http://yijiebuyi.com/blog/e310fc437f32006eb6aa42cad1783587.html
http://wdxtub.com/2016/02/18/oh-my-zsh/