# Global tags can be specified here in key="value" format. [global_tags] # dc = "us-east-1" # will tag all metrics with dc=us-east-1 # rack = "1a" ## Environment variables can be used as tags, and throughout the config file # user = "$USER"
# Configuration for influxdb server to send metrics to [[outputs.influxdb]] urls = ["http://172.172.172.96:8086"] database = "telegraf_metrics"
## Retention policy to write to. Empty string writes to the default rp. retention_policy = "" ## Write consistency (clusters only), can be: "any", "one", "quorum", "all" write_consistency = "any"
## Write timeout (for the InfluxDB client), formatted as a string. ## If not provided, will default to 5s. 0s means no timeout (not recommended). timeout = "5s" # username = "telegraf" # password = "2bmpiIeSWd63a7ew" ## Set the user agent for HTTP POSTs (can be useful for log differentiation) # user_agent = "telegraf" ## Set UDP payload size, defaults to InfluxDB UDP Client default (512 bytes) # udp_payload = 512
# Read metrics about cpu usage [[inputs.cpu]] ## Whether to report per-cpu stats or not percpu = true ## Whether to report total system cpu stats or not totalcpu = true ## Comment this line if you want the raw CPU time metrics fielddrop = ["time_*"]
# Read metrics about disk usage by mount point [[inputs.disk]] ## By default, telegraf gather stats for all mountpoints. ## Setting mountpoints will restrict the stats to the specified mountpoints. # mount_points = ["/"]
## Ignore some mountpoints by filesystem type. For example (dev)tmpfs (usually ## present on /run, /var/run, /dev/shm or /dev). ignore_fs = ["tmpfs", "devtmpfs"]
# Read metrics about disk IO by device [[inputs.diskio]] ## By default, telegraf will gather stats for all devices including ## disk partitions. ## Setting devices will restrict the stats to the specified devices. # devices = ["sda", "sdb"] ## Uncomment the following line if you need disk serial numbers. # skip_serial_number = false
# Get kernel statistics from /proc/stat [[inputs.kernel]] # no configuration
# Read metrics about memory usage [[inputs.mem]] # no configuration
# Get the number of processes and group them by status [[inputs.processes]] # no configuration
# Read metrics about swap memory usage [[inputs.swap]] # no configuration
# Read metrics about system load & uptime [[inputs.system]] # no configuration
# Read metrics about network interface usage [[inputs.net]] # collect data only about specific interfaces interfaces = ["ens192"]
g[eneral] NetworkManager's general status and operations n[etworking] overall networking control r[adio] NetworkManager radio switches c[onnection] NetworkManager's connections d[evice] devices managed by NetworkManager a[gent] NetworkManager secret agent or polkit agent m[onitor] monitor NetworkManager changes
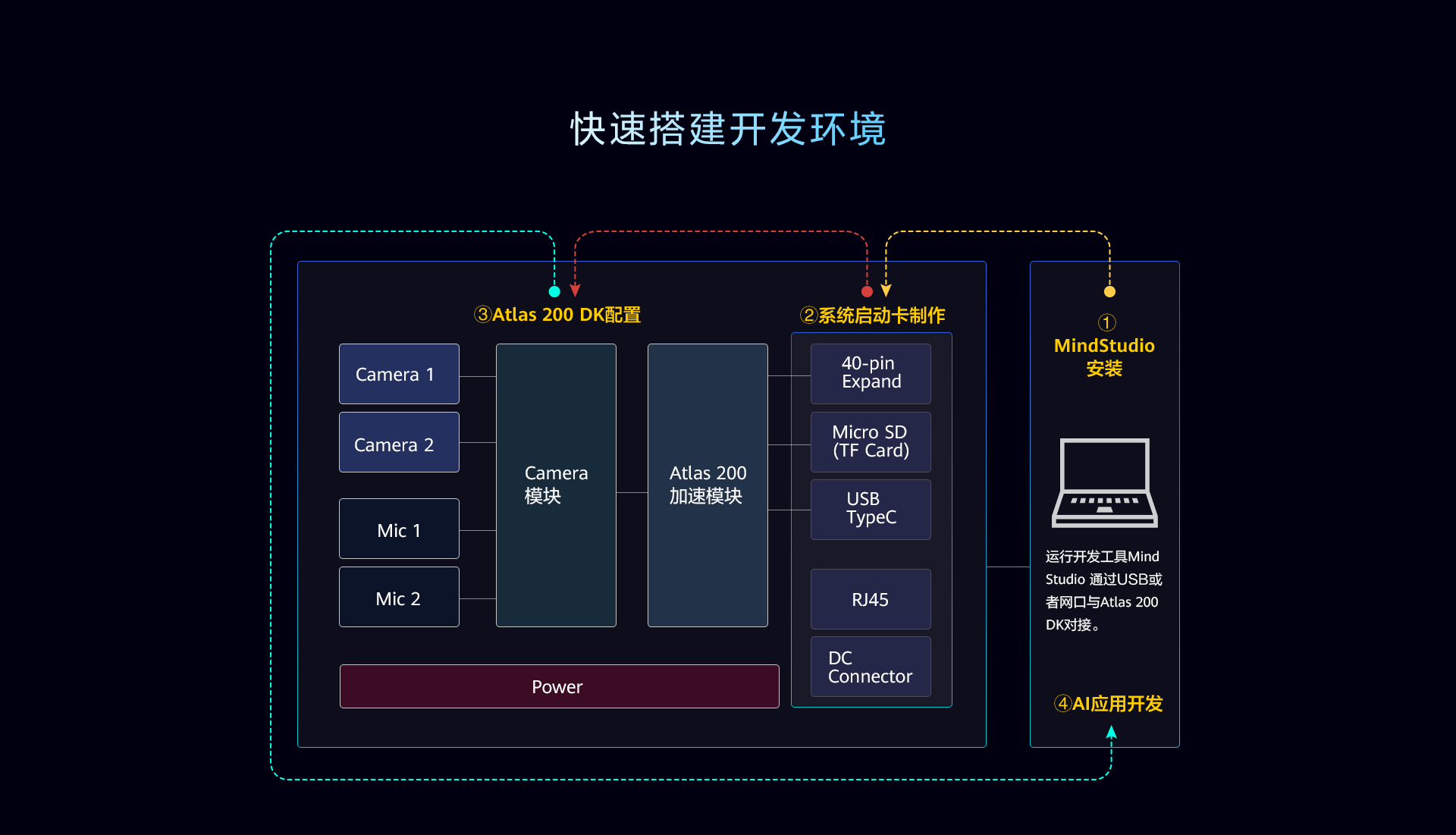
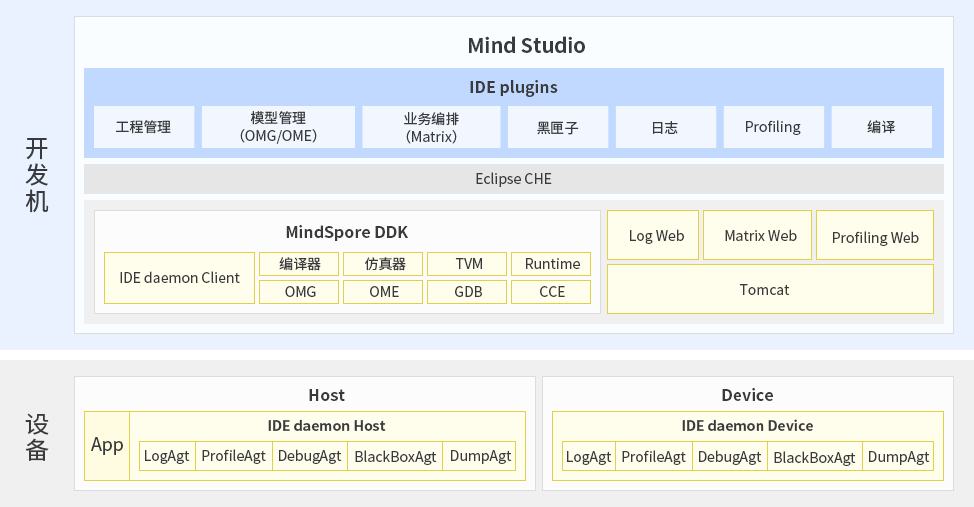
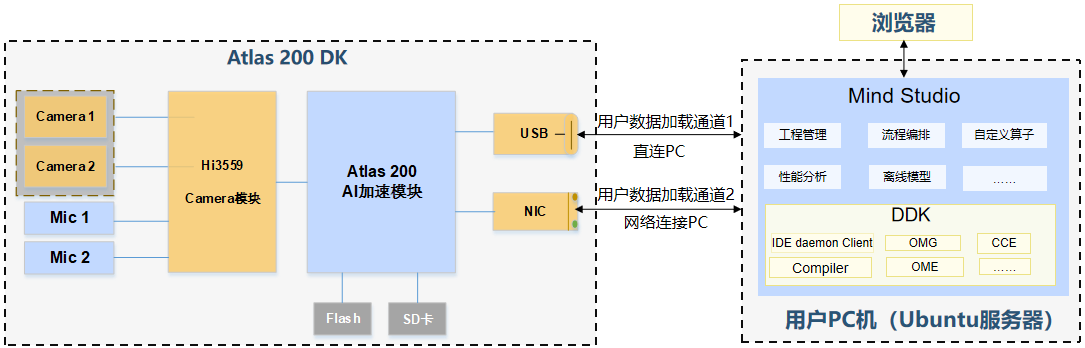
Mind Studio是一套基于华为昇腾AI处理器开发的AI全栈开发平台,提供了自定义算子的开发,网络层的网络移植、优化和分析等功能,另外在业务引擎层提供了一套可视化的AI引擎拖拽式编程服务,内置了丰富的高性能算子库,极大的降低了AI应用程序的开发门槛。
Mind Studio是基于Eclipse CHE架构的集成开发环境。 其中: DDK(Device Development Kit),为开发者提供了基于Ascend芯片的算法开发工具包,包括Host侧及Device侧开发编译时所依赖的库,开发机(UI Host)使用的工具及依赖库,以及一些公共头文件、第三方依赖库、DDK样例等